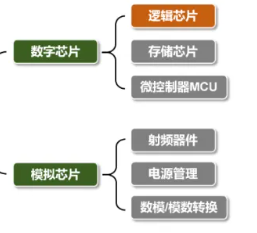
综述 #
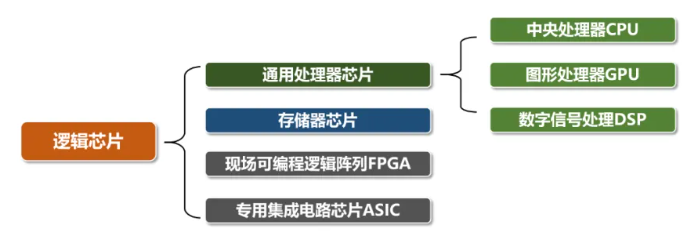

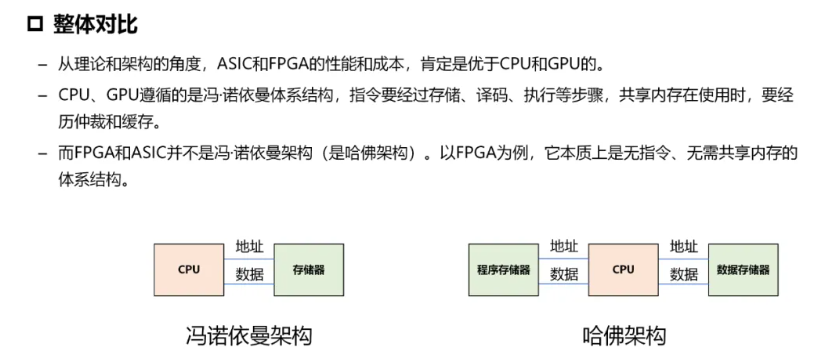

CPU #
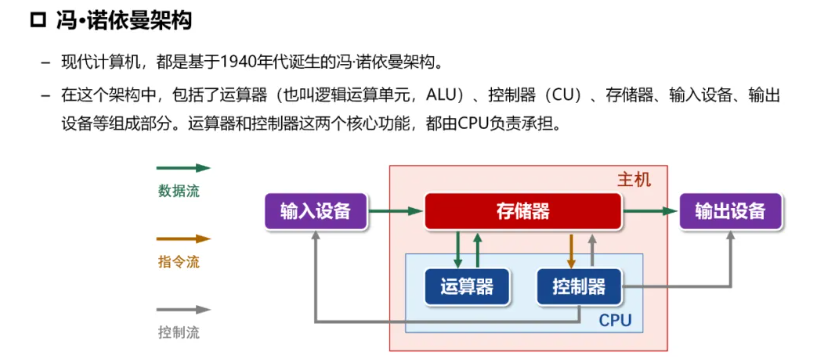
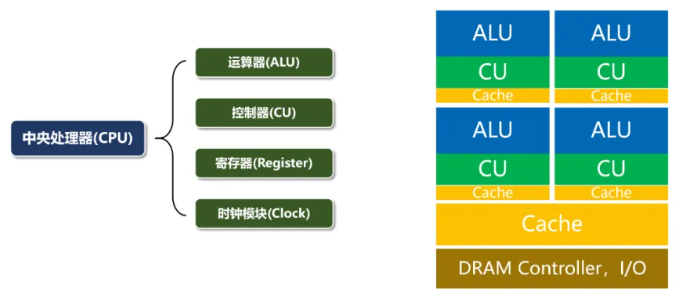
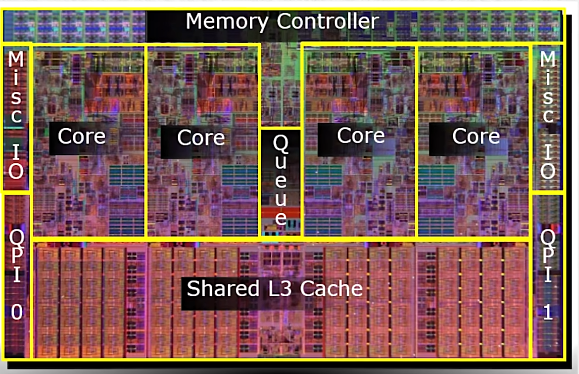
CPU类型 #
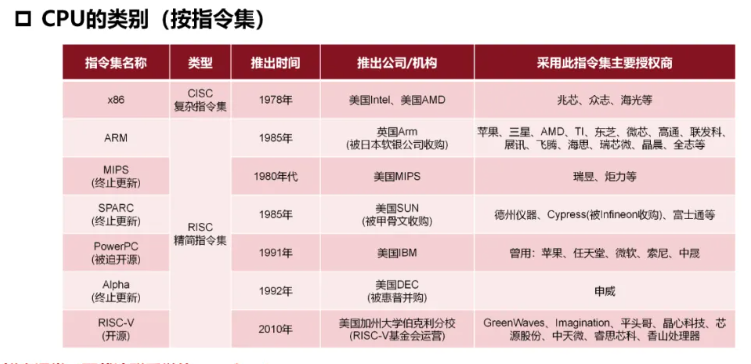
复杂指令集(CISC): x86, Zen
精简指令集(RISC):ARM,MIPS, PowerPC
- 针对性更强,可以根据不同的需求进行专门的优化,能效更高
- 调用速度快
- 服务器上往往使用RISC
- 服务器CPU往往应用了最先进的工艺和技术,并且配备了一二三级缓存,运行能力更强,服务器CPU很早就用上了3级缓存,普通cpu是近几年才用上了缓存技术
ARM #
是一个**32位精简指令集(RISC)**处理器架构
优势:价格低;能耗低
由于节能的特点,ARM处理器非常适用于行动通讯领域,符合其主要设计目标为低耗电的特性。
其广泛地使用在许多 嵌入式系统设计。
x86/Atom #
x86是英代尔Intel首先开发制造的一种
微处理器体系结构的泛称。
x86架构是重要地可变指令长度的CISC(复杂指令集电脑,Complex Instruction Set Computer)。
Intel Atom(中文:凌动,开发代号:Silverthorne)是Intel的一个
超低电压处理器系列
MIPS #
一种 RISC处理器
核心和线程 #
CPU可以想象成是一个银行,CPU核心就相当于柜员,而线程数就相当于开通了几个窗口,柜员和窗口越多,那么同时办理的业务就越多,速度也就越快。
通常情况下,一个柜员对应的是一个窗口,通过超线程技术相当于一个柜员管理着两个窗口,使用左右手同时办理两个窗口的业务,大大提高了核心的使用效率,增加了办理业务的速度。
#查看物理 cpu 数:
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
#查看每个物理 cpu 中 核心数(core 数):
cat /proc/cpuinfo | grep "cpu cores" | uniq
#查看总的逻辑 cpu 数(processor 数):
cat /proc/cpuinfo| grep "processor"| wc -l
#查看 cpu 型号:
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
#判断 cpu 是否 64 位:
#检查 cpuinfo 中的 flags 区段,看是否有 lm (long mode) 标识
2
48
96
Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50GHz
Thread(s) per core: 1
lscpu 命令可以同时看到上述信息。比如:
CPU(s): 24 On-line CPU(s) list: 0-23 Thread(s) per core: 2 Core(s) per socket: 6 Socket(s): 2
核心(core) #
一开始,每个物理 cpu 上只有一个核心(a single core),对操作系统而言,也就是同一时刻只能运行一个进程/线程。
总的逻辑 cpu 数 = 物理 cpu 数 * 每颗物理 cpu 的核心数 * 每个核心的超线程数
同时多线程技术(simultaneous multithreading) #
SMT
超线程技术(hyper–threading/HT) #
可以认为HT是 SMT 的一种具体技术实现
一般一个核心对应了一个线程,而intel开发出了超线程技术,1个核心能够做到2个线程计算,而6个核心则能够做到12个线程,超线程技术的好处就是无需增加物理核心就可以明显的进步CPU多线程功能,毕竟增加物理核心是需要占据非常大的核心面积,成本也随之增加
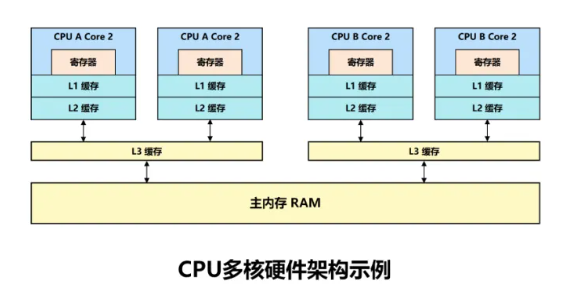
多核CPU #
GPU #
GPU主要参数 #

结构 #

相关厂商和产品 #
英伟达 #
常见计算卡(AI生成) #
计算卡对比 #
对比维度:
- 架构先进性: Hopper > Ada ≈ Ampere > Volta。
- 显存带宽: HBM3(H100) > HBM2e(A100) > GDDR6X(4090) > HBM2(V100)。
- 稀疏计算支持: H100/A100/4090显著优于旧架构。
- 多卡扩展: H100/A100支持NVLink,4090/3090仅支持PCIe。
综合来看:H100 > A100 ≈ A800 > RTX 4090 > A40 > V100 > RTX 3090 > A30
实际场景中,H100/A100更适合企业级训练,4090/3090适合个人或小规模任务,A40/A30侧重推理和边缘计算
H100 (Hopper架构) #
- 架构: Hopper (2022)
- 制程: 4nm
- 显存: 80GB HBM3 | 带宽 3TB/s
- 计算性能: FP32 60 TFLOPS | FP16/TF32 2,000 TFLOPS(稀疏)
- 核心数: 18,432 CUDA + 576 Tensor Core(第四代)
- 特性: 支持NVLink 4.0(900GB/s)、PCIe 5.0、Transformer引擎优化
- 功耗: 700W
- 定位: 超大规模模型训练、HPC
- 优势: Hopper架构 + 第四代Tensor Core + Transformer引擎,FP16稀疏算力高达 2,000 TFLOPS,HBM3显存带宽 3TB/s,支持NVLink 4.0,专为超大规模模型优化。
- 场景: 大规模训练(如GPT-4/LLaMA)、HPC。
A100 (Ampere架构) #
- 架构: Ampere (2020)
- 显存: 40GB/80GB HBM2e | 带宽 1.6TB/s
- 计算性能: FP32 19.5 TFLOPS | FP16/TF32 312 TFLOPS(稀疏)
- 核心数: 6,912 CUDA + 432 Tensor Core(第三代)
- 特性: NVLink 3.0(600GB/s)、多实例GPU(MIG)
- 功耗: 400W
- 定位: 主流AI训练、科学计算
A800 (Ampere架构) #
- 简介: A100的出口限制版,NVLink带宽降至400GB/s,其他参数与A100一致。
- 定位: 替代A100的中国市场专用型号。
A40 (Ampere架构) #
- 架构: Ampere (2021)
- 显存: 48GB GDDR6 | 带宽 696GB/s
- 计算性能: FP32 37.4 TFLOPS | FP16 149.8 TFLOPS
- 核心数: 10,752 CUDA + 336 Tensor Core
- 特性: 支持虚拟化、RT Core(光追)、被动散热
- 功耗: 300W
- 定位: 混合渲染与AI推理(如云游戏、虚拟化)。
- 优势: Ampere架构 + 第三代Tensor Core,FP16算力 149.8 TFLOPS,48GB GDDR6显存,支持虚拟化和光追。
- 局限: 显存带宽(696GB/s)低于HBM系列,适合混合渲染与推理。
- 场景: 云推理、虚拟化、轻量级训练。
V100 (Volta架构) #
- 架构: Volta (2017)
- 显存: 16GB/32GB HBM2 | 带宽 900GB/s
- 计算性能: FP32 14 TFLOPS | FP16 112 TFLOPS(Tensor Core)
- 核心数: 5,120 CUDA + 640 Tensor Core(第一代)
- 特性: NVLink 2.0(300GB/s)
- 功耗: 250W
- 定位: 经典深度学习卡,仍广泛用于推理和小规模训练。
- 优势: Volta架构 + 第一代Tensor Core,FP16算力 112 TFLOPS,HBM2显存带宽 900GB/s。
- 局限: 架构较老,稀疏计算支持有限。
- 场景: 经典推理任务、兼容性要求高的场景。
RTX 4090 (Ada Lovelace架构) #
- 架构: Ada Lovelace (2022)
- 显存: 24GB GDDR6X | 带宽 1TB/s
- 计算性能: FP32 82.6 TFLOPS | FP16 1321 TFLOPS(稀疏)
- 核心数: 16,384 CUDA + 512 Tensor Core(第四代)
- 功耗: 450W
- 定位: 单卡最强FP32性能,适合本地AI开发,但无ECC显存和NVLink。
- 优势: Ada架构 + 第四代Tensor Core,FP16算力 1,321 TFLOPS(稀疏),GDDR6X显存带宽 1TB/s,单卡FP32性能最强(82.6 TFLOPS)。
- 局限: 无ECC显存、不支持NVLink,显存容量(24GB)和带宽弱于H100/A100。
- 场景: 小规模训练、本地AI开发。
A30 (Ampere架构) #
- 架构: Ampere (2021)
- 显存: 24GB HBM2 | 带宽 933GB/s
- 计算性能: FP32 10.3 TFLOPS | FP16 82.5 TFLOPS
- 核心数: 3,584 CUDA + 112 Tensor Core
- 特性: 支持MIG、低功耗
- 功耗: 165W
- 定位: 高密度推理、边缘服务器。
- 优势: Ampere架构 + 第三代Tensor Core,FP16算力 82.5 TFLOPS,24GB HBM2显存,低功耗(165W)。
- 局限: 算力较低,适合高密度推理。
- 场景: 边缘服务器、批量推理。
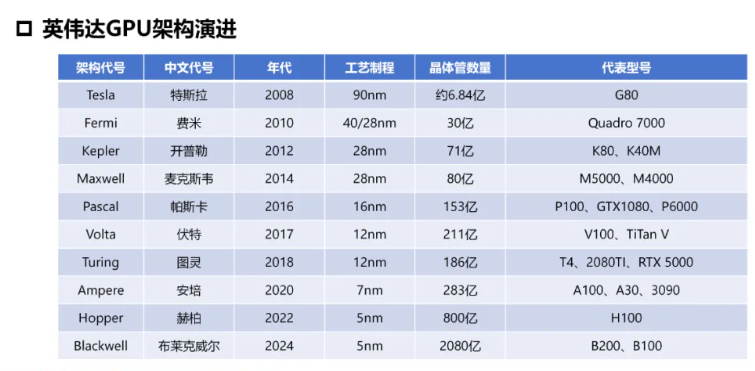
架构 #

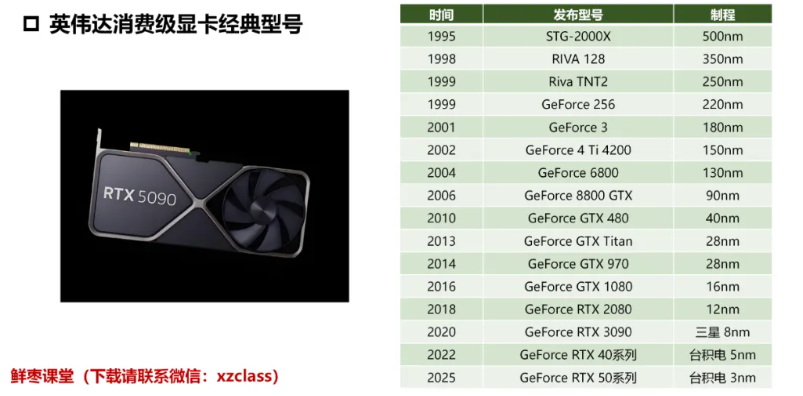
消费级显卡 #
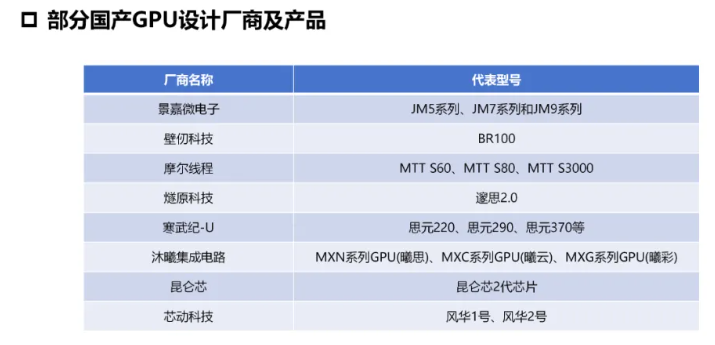
国产 #
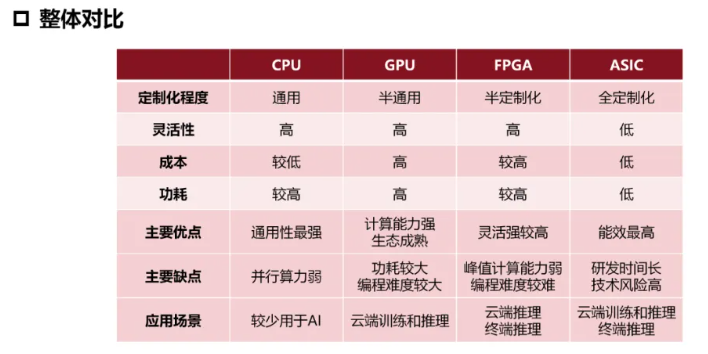
CPU和GPU区别 #

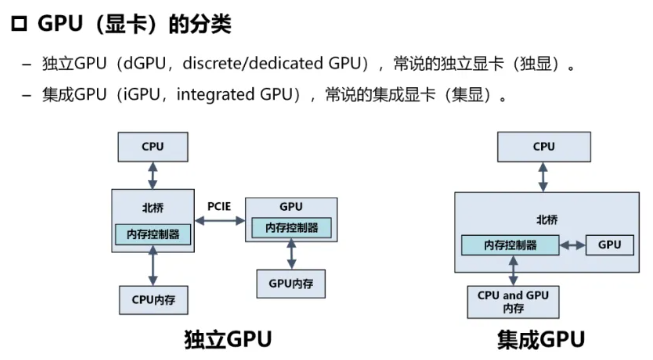
集显和独显 #
ASIC #




TPU #


NPU #

DPU #

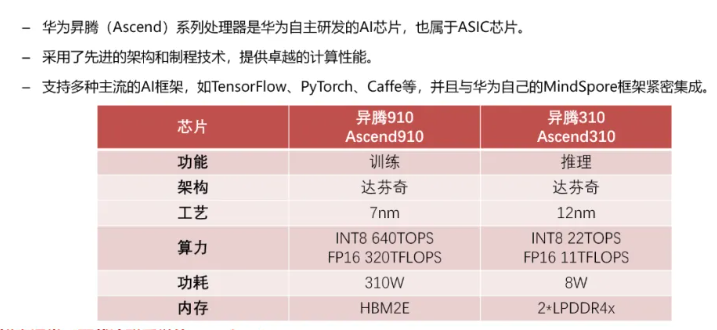
华为昇腾(Ascend) #
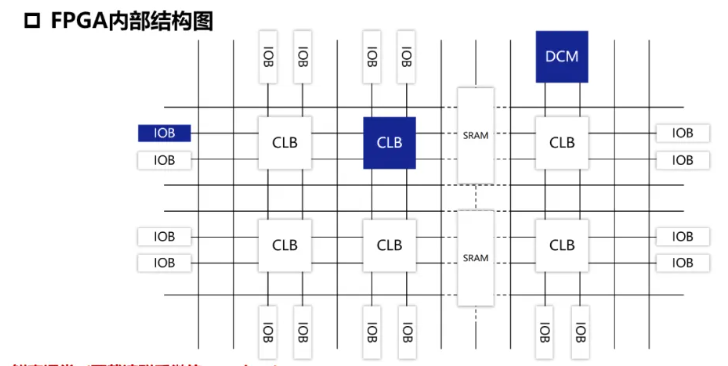
FPGA #