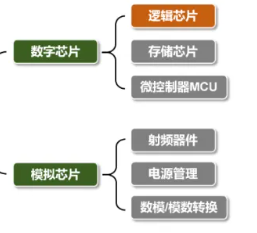
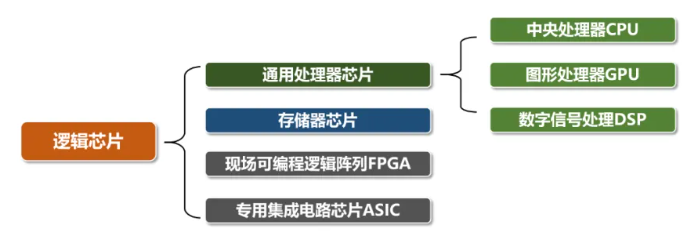
综述 #

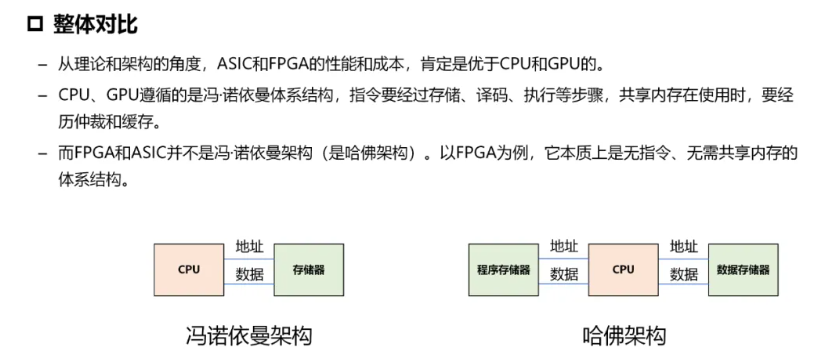

CPU #
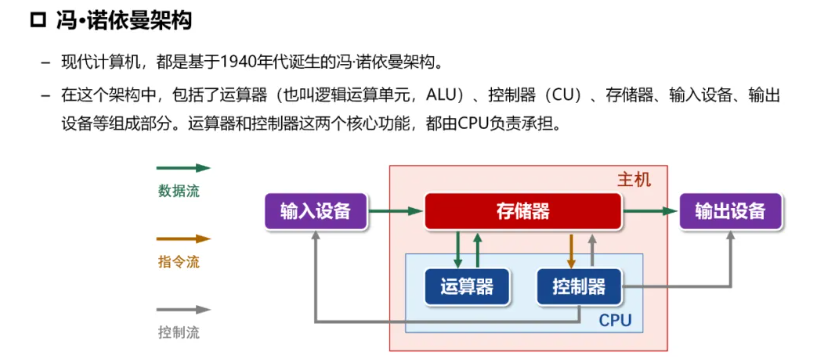
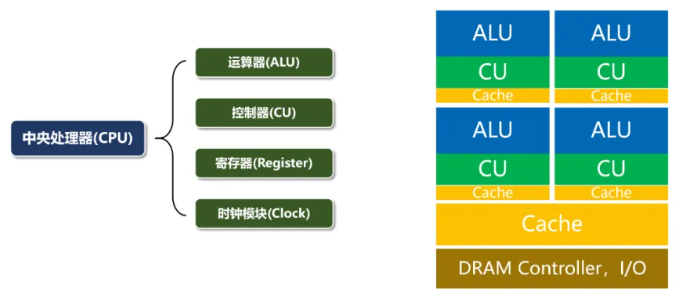
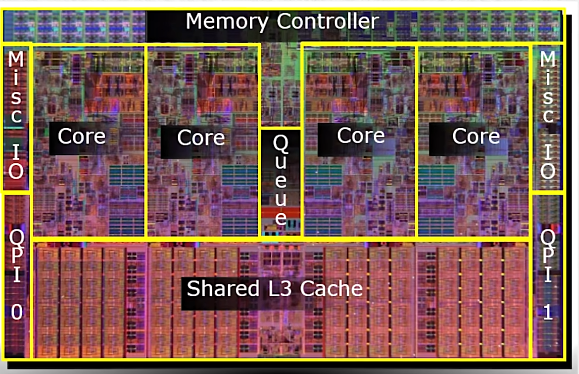
CPU类型 #
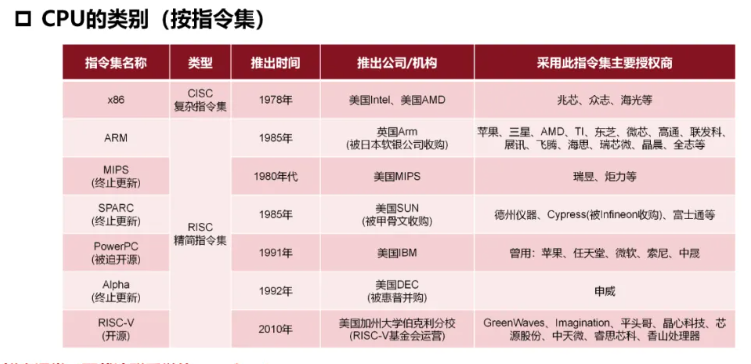
复杂指令集(CISC): x86, Zen
精简指令集(RISC):ARM,MIPS, PowerPC
- 针对性更强,可以根据不同的需求进行专门的优化,能效更高
- 调用速度快
- 服务器上往往使用RISC
- 服务器CPU往往应用了最先进的工艺和技术,并且配备了一二三级缓存,运行能力更强,服务器CPU很早就用上了3级缓存,普通cpu是近几年才用上了缓存技术
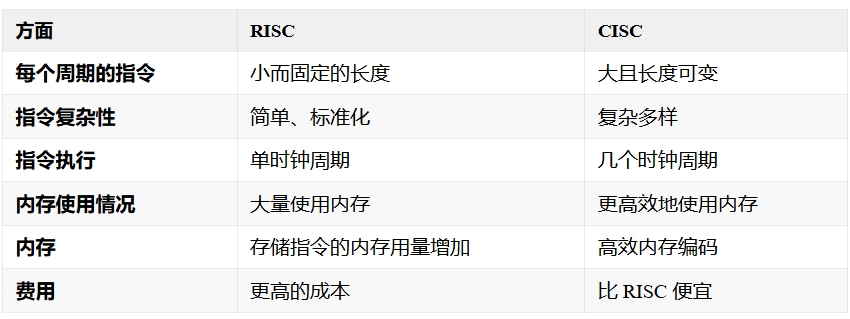
与 CISC 相比,RISC 方法有几个优点:
- 简化硬件实现:它简化了处理器的硬件实现,因为需要解码和执行的指令更少。这可加快执行时间,降低功耗。
- 更高的指令级并行性:RISC 处理器通常具有更高的指令级并行性,可同时执行多条指令,从而进一步提高性能。
- 简易性:RISC 指令集的简易性使得开发可为处理器生成高效代码的编译器和其他软件工具变得更加容易。
ARM #
是一个**32位精简指令集(RISC)**处理器架构
优势:价格低;能耗低
由于节能的特点,ARM处理器非常适用于行动通讯领域,符合其主要设计目标为低耗电的特性。
其广泛地使用在许多 嵌入式系统设计。
x86/Atom #
x86是英代尔Intel首先开发制造的一种
微处理器体系结构的泛称。
x86架构是重要地可变指令长度的CISC(复杂指令集电脑,Complex Instruction Set Computer)。
Intel Atom(中文:凌动,开发代号:Silverthorne)是Intel的一个
超低电压处理器系列
MIPS #
一种 RISC处理器(精简指令集)
RISC-V #
RISC-V(读作 risk-five)架构是一种开源指令集架构(ISA),近年来因其灵活性、模块化和可扩展性而备受关注
模块化是指将 ISA 划分为不同的独立组件,这些组件可以通过各种方式组合在一起,从而创建一个定制的处理器。另一方面,可扩展性是指在不破坏现有功能的情况下,向 ISA 添加新指令、功能或扩展的能力。
历史 #
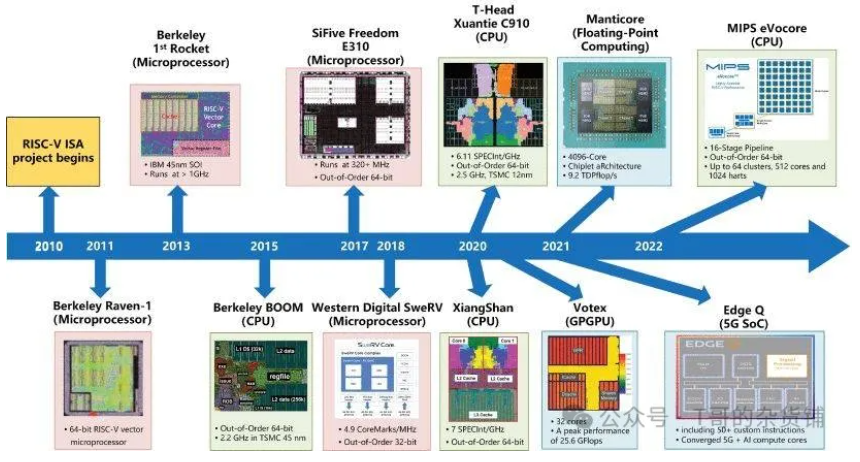
专有 ISA (例如 ARM) 受到特定公司的严格控制,限制了对其架构的访问,并征收许可费。这种缺乏开放性的做法阻碍了创新,打击了竞争,使小公司或学术机构在试验和开发定制处理器方面面临挑战。这导致了 RISC-V 的兴起。
在 RISC-V 之前,市场上有几种 RISC(精简指令集计算机)处理器。著名的例子包括 MIPS、SPARC 和 PowerPC。这些架构被认为是高效的,也有它们的应用,但它们往往需要支付许可费用,而且对其内部工作原理的访问也受到限制。
RISC-V 的起源可以追溯到 加利福尼亚大学伯克利分校,最初是作为 2010 年的一个研究项目开发的。该项目旨在创建一种全新的开源 ISA,以解决现有专有 ISA 的局限性,并为未来的处理器设计奠定基础。RISC-V 项目由计算机科学家 Krste Asanović、Yunsup Lee 和 Andrew Waterman 领导,他们受到开源软件成功的启发,希望为硬件领域带来类似的好处。
第一版 RISC-V ISA 于 2011 年发布,被称为 “RV32I " 基本整数指令集。最初的版本遵循精简指令集计算(RISC)原则,注重简洁和高效。多年来,RISC-V ISA 经历了多次迭代,增加了新的扩展和功能,以增强其功能,满足更广泛的应用需求。
2015 年,RISC-V 基金会成立,旨在促进 RISC-V ISA 的采用和标准化。该基金会汇集了行业领导者、学术机构和个人贡献者,共同合作开发和推广 RISC-V 技术。自成立以来,RISC-V 基金会已发展了 200 多个成员组织,RISC-V ISA 已被众多公司采用,应用于从微控制器和嵌入式系统到高性能计算和数据中心处理器等各种领域。
核心和线程 #
CPU可以想象成是一个银行,CPU核心就相当于柜员,而线程数就相当于开通了几个窗口,柜员和窗口越多,那么同时办理的业务就越多,速度也就越快。
通常情况下,一个柜员对应的是一个窗口,通过超线程技术相当于一个柜员管理着两个窗口,使用左右手同时办理两个窗口的业务,大大提高了核心的使用效率,增加了办理业务的速度。
#查看物理 cpu 数:
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
#查看每个物理 cpu 中 核心数(core 数):
cat /proc/cpuinfo | grep "cpu cores" | uniq
#查看总的逻辑 cpu 数(processor 数):
cat /proc/cpuinfo| grep "processor"| wc -l
#查看 cpu 型号:
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
#判断 cpu 是否 64 位:
#检查 cpuinfo 中的 flags 区段,看是否有 lm (long mode) 标识
2
48
96
Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50GHz
Thread(s) per core: 1
lscpu 命令可以同时看到上述信息。比如:
CPU(s): 24 On-line CPU(s) list: 0-23 Thread(s) per core: 2 Core(s) per socket: 6 Socket(s): 2
核心(core) #
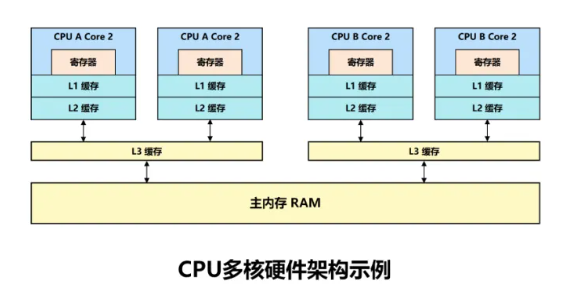
一开始,每个物理 cpu 上只有一个核心(a single core),对操作系统而言,也就是同一时刻只能运行一个进程/线程。
总的逻辑 cpu 数 = 物理 cpu 数 * 每颗物理 cpu 的核心数 * 每个核心的超线程数
同时多线程技术(simultaneous multithreading) #
SMT
超线程技术(hyper–threading/HT) #
可以认为HT是 SMT 的一种具体技术实现
一般一个核心对应了一个线程,而intel开发出了超线程技术,1个核心能够做到2个线程计算,而6个核心则能够做到12个线程,超线程技术的好处就是无需增加物理核心就可以明显的进步CPU多线程功能,毕竟增加物理核心是需要占据非常大的核心面积,成本也随之增加
多核CPU #
GPU #
GPU主要参数 #

结构 #

软硬件结构的对应 #
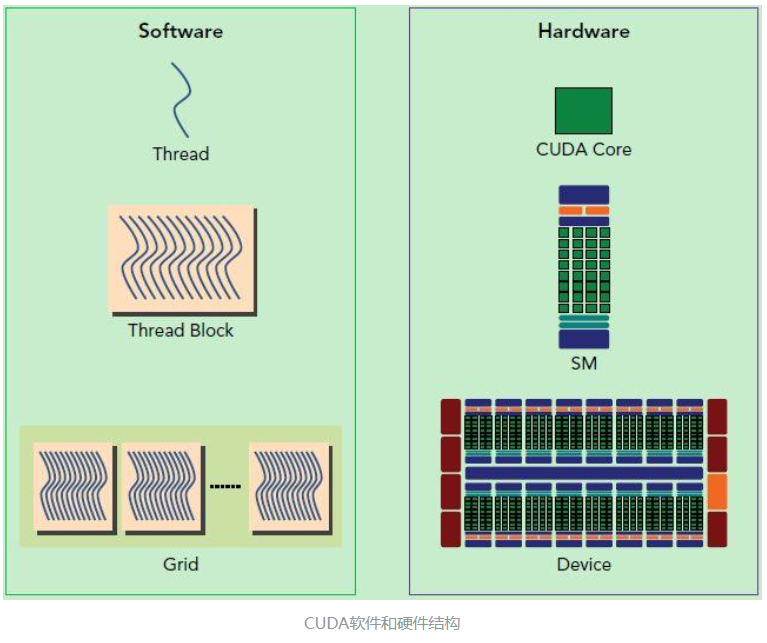
SP(Streaming Processor)/CUDA core:流处理器, 是GPU最基本的处理单元,。相当于一个threadSM(Streaming MultiProcessor): 一个SM由多个CUDA core组成,每个SM根据GPU架构不同有不同数量的CUDA core,Pascal架构中一个SM有128个CUDA core。 SM还包括特殊运算单元(SFU),共享内存(shared memory),寄存器文件(Register File)和==调度器==(Warp Scheduler)等。==register和shared memory是稀缺资源==,这些有限的资源就使每个SM中active warps有非常严格的限制,也就限制了并行能力。warp: 一个CUDA core可以执行一个thread,一个SM的CUDA core会分成几个warp(即CUDA core在SM中分组),由 warp scheduler负责调度。尽管warp中的线程从同一程序地址,但可能具有不同的行为,比如分支结构,因为==GPU规定warp中所有线程在同一周期执行相同的指令==,warp发散会导致性能下降。一个SM同时并发的warp是有限的,因为资源限制,SM要为每个线程块分配共享内存,而也要为每个线程束中的线程分配独立的寄存器,所以SM的配置会影响其所支持的线程块和warp并发数量。由于warp的大小一般为32,所以block所含的thread的大小一般要设置为32的倍数每个block的warp数量:
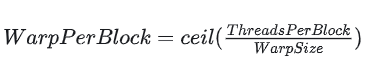
一个warp中的线程必然在同一个block中,如果block所含线程数目不是warp大小的整数倍,那么多出的那些thread所在的warp中,会剩余一些inactive的thread
相关厂商和产品 #
英伟达 #
常见计算卡(AI生成) #
计算卡对比 #
对比维度:
- 架构先进性: Hopper > Ada ≈ Ampere > Volta。
- 显存带宽: HBM3(H100) > HBM2e(A100) > GDDR6X(4090) > HBM2(V100)。
- 稀疏计算支持: H100/A100/4090显著优于旧架构。
- 多卡扩展: H100/A100支持NVLink,4090/3090仅支持PCIe。
综合来看:H100 > A100 ≈ A800 > RTX 4090 > A40 > V100 > RTX 3090 > A30
实际场景中,H100/A100更适合企业级训练,4090/3090适合个人或小规模任务,A40/A30侧重推理和边缘计算
H100 (Hopper架构) #
- 架构: Hopper (2022)
- 制程: 4nm
- 显存: 80GB HBM3 | 带宽 3TB/s
- 计算性能: FP32 60 TFLOPS | FP16/TF32 2,000 TFLOPS(稀疏)
- 核心数: 18,432 CUDA + 576 Tensor Core(第四代)
- 特性: 支持NVLink 4.0(900GB/s)、PCIe 5.0、Transformer引擎优化
- 功耗: 700W
- 定位: 超大规模模型训练、HPC
- 优势: Hopper架构 + 第四代Tensor Core + Transformer引擎,FP16稀疏算力高达 2,000 TFLOPS,HBM3显存带宽 3TB/s,支持NVLink 4.0,专为超大规模模型优化。
- 场景: 大规模训练(如GPT-4/LLaMA)、HPC。
A100 (Ampere架构) #
- 架构: Ampere (2020)
- 显存: 40GB/80GB HBM2e | 带宽 1.6TB/s
- 计算性能: FP32 19.5 TFLOPS | FP16/TF32 312 TFLOPS(稀疏)
- 核心数: 6,912 CUDA + 432 Tensor Core(第三代)
- 特性: NVLink 3.0(600GB/s)、多实例GPU(MIG)
- 功耗: 400W
- 定位: 主流AI训练、科学计算
A800 (Ampere架构) #
- 简介: A100的出口限制版,NVLink带宽降至400GB/s,其他参数与A100一致。
- 定位: 替代A100的中国市场专用型号。
A40 (Ampere架构) #
- 架构: Ampere (2021)
- 显存: 48GB GDDR6 | 带宽 696GB/s
- 计算性能: FP32 37.4 TFLOPS | FP16 149.8 TFLOPS
- 核心数: 10,752 CUDA + 336 Tensor Core
- 特性: 支持虚拟化、RT Core(光追)、被动散热
- 功耗: 300W
- 定位: 混合渲染与AI推理(如云游戏、虚拟化)。
- 优势: Ampere架构 + 第三代Tensor Core,FP16算力 149.8 TFLOPS,48GB GDDR6显存,支持虚拟化和光追。
- 局限: 显存带宽(696GB/s)低于HBM系列,适合混合渲染与推理。
- 场景: 云推理、虚拟化、轻量级训练。
V100 (Volta架构) #
- 架构: Volta (2017)
- 显存: 16GB/32GB HBM2 | 带宽 900GB/s
- 计算性能: FP32 14 TFLOPS | FP16 112 TFLOPS(Tensor Core)
- 核心数: 5,120 CUDA + 640 Tensor Core(第一代)
- 特性: NVLink 2.0(300GB/s)
- 功耗: 250W
- 定位: 经典深度学习卡,仍广泛用于推理和小规模训练。
- 优势: Volta架构 + 第一代Tensor Core,FP16算力 112 TFLOPS,HBM2显存带宽 900GB/s。
- 局限: 架构较老,稀疏计算支持有限。
- 场景: 经典推理任务、兼容性要求高的场景。
RTX 4090 (Ada Lovelace架构) #
- 架构: Ada Lovelace (2022)
- 显存: 24GB GDDR6X | 带宽 1TB/s
- 计算性能: FP32 82.6 TFLOPS | FP16 1321 TFLOPS(稀疏)
- 核心数: 16,384 CUDA + 512 Tensor Core(第四代)
- 功耗: 450W
- 定位: 单卡最强FP32性能,适合本地AI开发,但无ECC显存和NVLink。
- 优势: Ada架构 + 第四代Tensor Core,FP16算力 1,321 TFLOPS(稀疏),GDDR6X显存带宽 1TB/s,单卡FP32性能最强(82.6 TFLOPS)。
- 局限: 无ECC显存、不支持NVLink,显存容量(24GB)和带宽弱于H100/A100。
- 场景: 小规模训练、本地AI开发。
A30 (Ampere架构) #
- 架构: Ampere (2021)
- 显存: 24GB HBM2 | 带宽 933GB/s
- 计算性能: FP32 10.3 TFLOPS | FP16 82.5 TFLOPS
- 核心数: 3,584 CUDA + 112 Tensor Core
- 特性: 支持MIG、低功耗
- 功耗: 165W
- 定位: 高密度推理、边缘服务器。
- 优势: Ampere架构 + 第三代Tensor Core,FP16算力 82.5 TFLOPS,24GB HBM2显存,低功耗(165W)。
- 局限: 算力较低,适合高密度推理。
- 场景: 边缘服务器、批量推理。
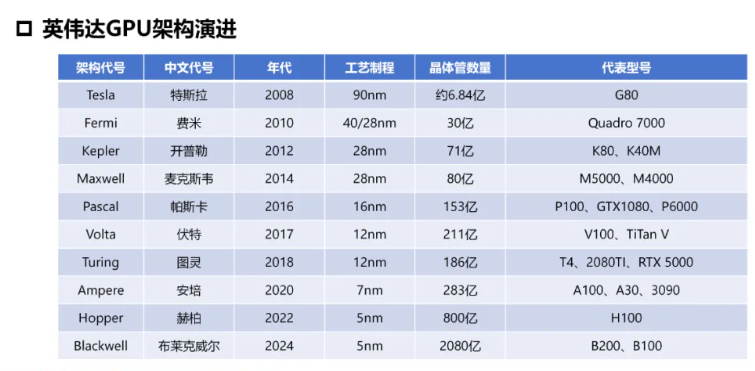
架构 #

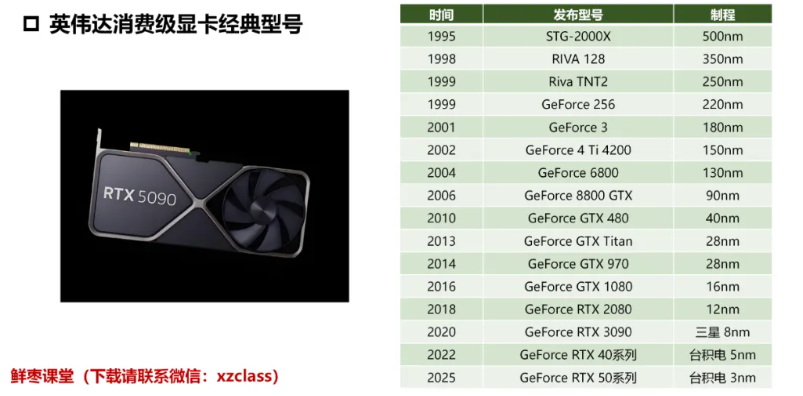
消费级显卡 #
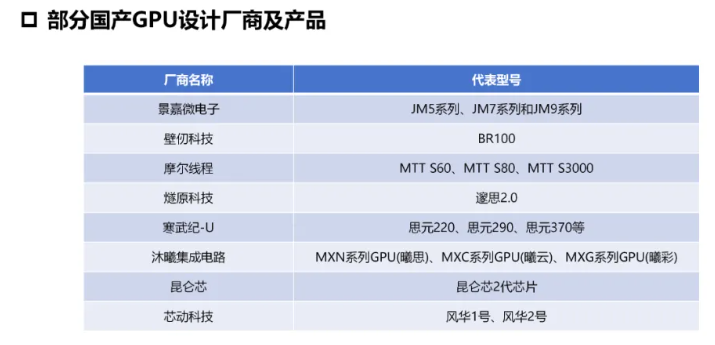
国产 #
| Parameter | MTT S4000 | NVIDIA H100 |
|---|---|---|
| Architecture | 3rd generation MUSA architecture | Hopper architecture |
| Manufacturing Process | ==16nm== process technology | 4N custom process from TSMC |
| Memory Capacity | 48GB GDDR6 | 80GB HBM3 (SXM) / 94GB HBM3 (NVL) |
| Memory Bandwidth | 768GB/s | 3.35TB/s (SXM) / 3.9TB/s (NVL) |
| Compute Performance (FP32) | 25 TFLOPs | 67 TFLOPs |
| Tensor Core Performance (FP16/BF16) | 1,979 TFLOPs | 1,979 TFLOPs (with sparsity) |
| Interconnect Technology | MTLink technology (240GB/s data link from one card to another) | NVIDIA NVLink™ (900GB/s) / PCIe Gen5 (128GB/s) |
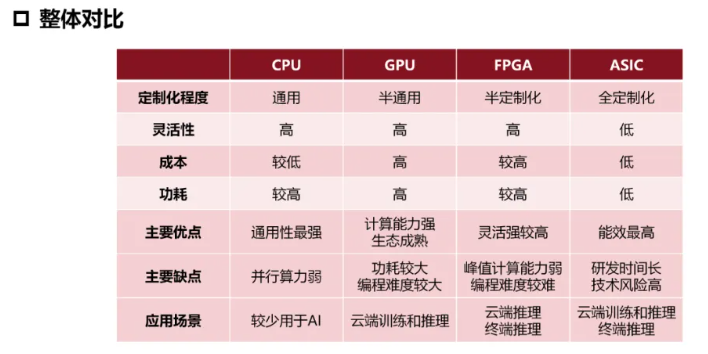
CPU和GPU区别 #

相比CPU,GPU将更多的晶体管用于数值计算,而不是缓存和流控(Flow Control)。这源于两者不同的设计目标,CPU的设计目标是并行执行几十个线程,而GPU的目标是要并行执行几千个线程
GPU的Core数量要远远多余CPU,但是有得必有失,可以看到GPU的Cache和Control要远远少于CPU,这使得GPU的单Core的自由度要远远低于CPU,会受到诸多限制,而这个限制==最终会由程序员承担==。这些限制也使得GPU编程与CPU多线程编程有着根本区别。
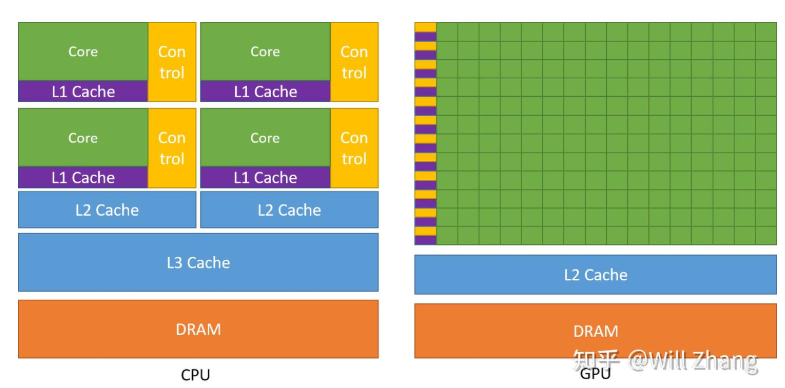
这其中最根本的一个区别可以在上右图中看出,每一行有多个Core,却只有一个Control,这代表着==多个Core同一时刻只能执行同样的指令==,这种模式也称为 SIMT (Single Instruction Multiple Threads). 这与现代CPU的SIMD倒是有些相似,但却有根本差别
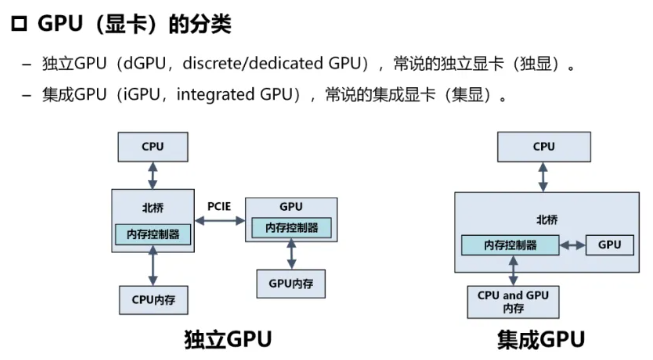
集显和独显 #
ASIC #




TPU #


NPU #

DPU #

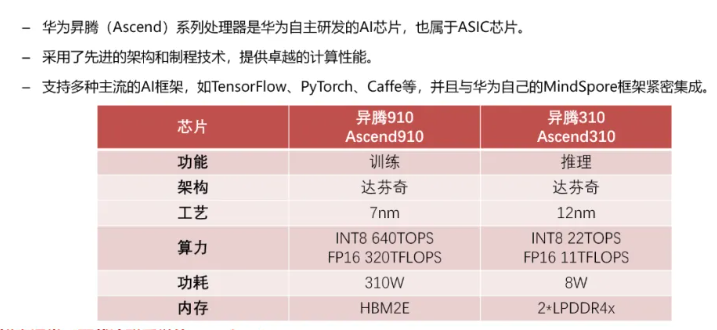
华为昇腾(Ascend) #
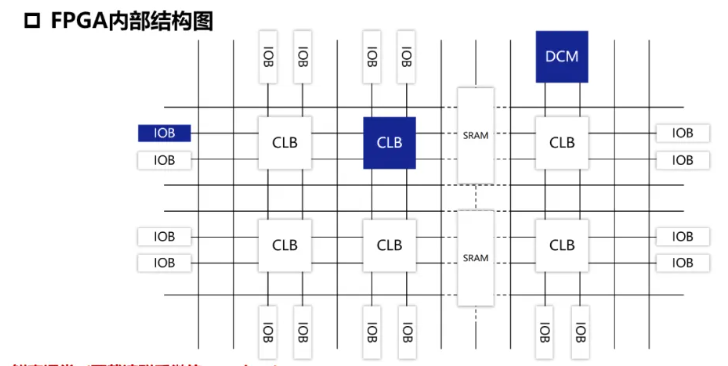
FPGA #