C/C++ #
key word #
extern #
extern可以置于变量或者函数前,以标示变量或者函数的定义在别的文件中,提示编译器遇到此变量和函数时在其他模块中寻找其定义。此外extern也可用来进行链接指定
register #
union #
volatile #
C++ only keywords #

class #
#include <iostream>
#include <string>
using namespace std;
class Person {
private://私有成员只能在类内部访问。
string name;
int age;
public://公有成员可以在类外部访问。
//static 关键字可以用于类成员变量或成员函数,表示它们属于类本身,而不是类的某个特定对象
static int totalPopulation;
//构造函数是一种特殊的成员函数,用于初始化对象。它与类同名,没有返回类型,也不返回任何值。
Person(string n, int a) : name(n), age(a) {
totalPopulation++; // 每次创建新对象时增加人数
} // 构造函数
virtual void display() const {//如果你想在派生类中重写基类的虚函数,基类的函数必须被声明为 virtual
cout << "Name: " << name << ", Age: " << age << endl;
}
friend void displayPerson(const Person &p);//友元函数是类外部的函数,可以访问类的私有和保护成员。
//操作符重载
Person& operator++() { // 前置++
++age;
return *this;
}
//操作符重载
Person operator++(int) { // 后置++
Person temp = *this;
++(*this);
return temp;
}
//静态函数
static void displayTotalPopulation()
{
cout << "Total population: " << totalPopulation << endl;
}
~Person()
{
totalPopulation--; // 每次析构对象时减少人数
} // 析构函数用于在对象生命周期结束时进行清理工作。它与类同名,前面加上 ~,没有参数,也没有返回类型。
};
int Person::totalPopulation = 0; // 静态成员变量的初始化!
void displayPerson(const Person &p) {//友元函数, 在类内声明过了,可以访问类的私有和保护成员。
cout << "Name: " << p.name << ", Age: " << p.age << endl;
}
//继承
class Student : public Person {
private:
string school;
public:
Student(string n, int a, string s) : Person(n, a), school(s) {}
void display() const override {
Person::display();
cout << "School: " << school << endl;
}
};
int main() {
Person person("Alice", 30);
person.display();
//通过基类指针或引用调用派生类
Person *p1 = new Person("Alice", 30);
Person *p2 = new Student("Bob", 20, "MIT");
p1->display();
p2->display();
cout<< "total population = " << Person::totalPopulation <<endl;
Person::displayTotalPopulation();
delete p1;
delete p2;
++person;
person.display();
person++;
person.display();
displayPerson(person);//友元函数
return 0;
}
//类模板允许你创建通用类,可以处理任何数据类型。
template <typename T>
class Stack {
private:
std::vector<T> elements;
public:
void push(const T& element) {
elements.push_back(element);
}
T pop() {
T elem = elements.back();
elements.pop_back();
return elem;
}
};
int main() {
Stack<int> intStack;
intStack.push(1);
intStack.push(2);
std::cout << intStack.pop() << std::endl; // 输出 2
std::cout << intStack.pop() << std::endl; // 输出 1
return 0;
}
copy,move构造函数,
左/右值引用 #
左值引用& #
右值引用&& #
- 一次性使用:右值引用只能绑定到右值上,一旦绑定,原始的右值就不能再被使用。
- 移动语义:右值引用允许你转移资源的所有权,而不是复制资源。这是通过移动构造函数和移动赋值运算符实现的。
- 临时对象:右值引用可以用来延长临时对象的生命周期,使其可以被多次使用。
- 完美转发:右值引用在模板编程中用于完美转发参数,这样可以保留参数的左值或右值性质。
指针 #
野指针和空指针 #
空指针: 如 int *p = NULL 这就定义了一个指针,通常NULL是一个零值,操作系统定义内存64kb以下的内存单元是不可访问的,所以像如 *p = 9 这样给他赋值是系统不允许的,将会发生内存报错。
野指针: 如 int *p就是一个野指针,可以看到它在创建时没有赋初值,所以它的值是一个随机数,也就是乱指一气,通常都是指向了不合法的内存段,所以使用它也会内存报错。还有指针p被free或者delete之后也会成为野指针,因为它所指的内存空间被释放之后,变成了一个不合法内存段。野指针,它顾名思义它就是一个野指针,它是没有主人领养的野兽,凶猛残暴,用它你就得自食其果。
指针的魅力 #
场景1:使一个字符串颠倒顺序 #
void reverse(char *_str,int _l) //反转函数,_l指要反转字串的长度
{
char *p=_str,*q=_str+_l-1,temp; //指针直接得到值
while(q>p)
{
temp=*p;
*p=*q;
*q=temp;
p++;
q--;
}
}
void reverse(char *_str,int _l) //反转函数,_l指要反转字串的长度
{
int i=0,j=_l-1,temp;
while(j>i)
{
temp=str[i];
str[i]=str[j];
str[j]=str[i];
i++;
j--;
}
}
这样并不比上面用迭代器的情况好,而且要糟很多,因为这样用str[i],str[j]的下标的方式访问元素时,需要先对str所存的数组首地址进行一次加减运算才能正确得到第i个、第j个值(读者可在任何一款编译器上进行反汇编查看),上面一共出现了5次下标访问str元素,情况可想而知。
场景2:函数传递 #
typedef struct structType
{
int i;
char arr[100];
}structType;
//一个print函数的定义:
void print0(const structType data)
{
//printf something about data
}
//另一个print函数的定义:
void print1(const structType *pdata)
{
//printf something about data
}
print1比print0有明显的效率优势,因为print0是值传递,当值传进去时,必须要开辟一个structType那么大的内存空间来乘装这些值,这就要相当大的一部分资源消耗,而print1是指针传递,传进去的是地址,一个地址只需4字节内存空间,使用时解析其指针即可,因此它比print0更高效更实用。
场景3 #
在C++中,使用std::vector存储类对象时,你可以选择存储对象的实例(直接存储变量)或者对象的指针。这两种方式各有优缺点:
直接存储对象(对象实例) #
优点:
- 简单易用:不需要管理内存,
std::vector会自动管理对象的生命周期。 - 性能:不需要额外的间接寻址,直接访问对象。
- 安全性:对象生命周期由
std::vector管理,减少了内存泄漏的风险。
缺点:
- 拷贝开销:当对象较大时,复制对象可能会有性能开销。
- 灵活性:如果需要存储不同类型的对象,可能需要使用虚函数和基类指针。
存储对象指针 #
优点:
- 灵活性:可以存储不同类型的对象,只要它们继承自同一个基类。
- 性能:对于大型对象,存储指针可以避免复制开销。
缺点:
- 内存管理:需要手动管理对象的内存,容易出错。
- 间接寻址:访问对象属性或方法时需要额外的间接寻址,可能会有轻微的性能开销。
- 复杂性:代码复杂度增加,需要考虑对象的创建和销毁。
选择建议 #
- 如果对象较小且不需要存储多种类型的对象,直接存储对象实例通常更简单、更安全。
- 如果对象较大或需要存储多种类型的对象,存储指针可能更合适,但需要小心管理内存。
vector&数组&链表与栈&堆 #
数组 #
用来存储固定大小的同类型元素的序列
特点 #
- 固定大小:创建时需要指定数组的大小,之后无法更改。
- 随机访问:可以直接通过索引快速访问任何元素,时间复杂度为 O(1)。
- 高效的内存利用:由于连续的内存分配,数组在内存利用和访问速度方面非常高效。
- 插入/删除操作耗时:在数组中间插入或删除元素通常需要移动其他元素,因此这些操作的时间复杂度较高。
- 数组的限制:数组的大小在声明时必须确定,且不能改变,数组不提供检查越界的机制,访问无效索引可能导致未定义行为。
vector #
向量(Vector,如 std::vector)随机访问快,时间复杂度为 O(1),插入/删除操作慢,在末尾快,但在中间或开始较慢,内存动态分配,可以根据需要改变大小,但可能涉及复制整个数组到新的内存位置。适用场景:当需要动态数组,即数组大小可以改变的场景,需要随机访问,但也会有在末尾添加或删除元素的操作场景。
特点 #
- 动态大小:向量可以在运行时根据需要扩展或缩减其大小。
- 随机访问:与数组一样,向量支持通过索引的快速随机访问。
- 自动管理内存:向量在内部管理内存,自动扩展和缩减存储空间。
- 可能的重新分配开销:当向量扩展到超过当前分配的内存时,它可能需要重新分配整个内存块来存储元素。
- 由于动态扩容,向量的内存使用可能不如静态数组高效, 在频繁扩容的情况下,性能可能受到影响。
链表 #
链表是一种由节点组成的数据结构,每个节点包含数据和指向下一个节点的指针,链表中的元素不必在内存中连续存储,这种情况下频繁插入和删除时,链表会更加高效,但是不支持随机访问,访问特定索引的元素需要从头开始遍历,效率较低。
C++ 标准库提供了两种链表类型:std::list:双向链表 和 std::forward_list:单向链表
std::forward_list 提供了单向链表的实现,适合于需要频繁在头部插入或删除元素的场景。由于其单向特性,它在内存使用上比 std::list 更高效,但也牺牲了一些灵活性,如无法直接访问前一个元素。
特点 #
- 动态大小:链表的大小可以根据需要动态变化。
- 高效的插入和删除:可以在任何位置快速地插入或删除节点,不需要移动其他元素。
- 无随机访问:访问链表中的元素需要从头开始遍历,时间复杂度为 O(n)。
- 额外的内存开销:每个节点需要额外的存储空间来存储指针。
智能指针 #
内存泄漏&悬空指针 #
举例 #
void foo(int n) {
int* ptr = new int(42);
...
if (n > 5) {
return;
}
...
delete ptr;
}
void other_fn(int* ptr) {
...
};
void bar() {
int* ptr = new int(42);
other_fn(ptr);
// ptr == ?
}
在foo函数中,如果入参n > 5, 则会导致指针ptr的内存未被正确释放,从而导致内存泄漏。
在bar函数中,我们将指针ptr传递给了另外一个函数other_fn,我们无法确定other_fn有没有释放ptr内存,如果被释放了,那ptr将成为一个悬空指针,bar在后续还继续访问它,会引发未定义行为,可能导致程序崩溃。
unique_ptr #
在超出作用域时,会自动释放所管理的对象内存
#include <memory>
#include <iostream>
class MyClass {
public:
MyClass() {
std::cout << "MyClass constructed" << std::endl;
}
~MyClass() {
std::cout << "MyClass destroyed" << std::endl;
}
};
int main() {
std::unique_ptr<MyClass> ptr1(new MyClass);
return 0;
}
MyClass constructed MyClass destroyed
shared_ptr #
shared_ptr是C++11提供的另外一种常见的智能指针,与unique_ptr独占对象方式不同,shared_ptr是一种共享式智能指针,允许多个shared_ptr指针共同拥有同一个对象,采用引用计数的方式来管理对象的生命周期。当所有的 shared_ptr 对象都销毁时,才会自动释放所管理的对象。
Bugs #
1. #
vector
var1[m][n];//不行 vector<vector<vector » var2[m][n];//可以
//当wire_max_level和wire_max_sublevel较大(1000)时,初始化第258和259行的 “IntVec dst[wire_max_level][wire_max_sublevel];IntVec dst_ports[wire_max_level][wire_max_sublevel];”会报错:Segmentation fault
在C++中,这两种声明方式涉及到多维向量的初始化和存储方式,它们之间存在一些关键的差异:
vector
问题: 栈溢出:如果 m 和 n 较大,这种声明可能会因为栈空间不足而导致编译错误或运行时错误(如段错误)。 未定义行为:在C++标准中,这种用法是未定义的,因为 vector 需要动态内存分配,而数组的静态内存分配无法满足这一需求。
vector<vector<vector
特点: 堆分配:尽管 vector 通常在堆上分配内存,但这种声明方式实际上在栈上创建了一个指向 vector 的指针数组,每个指针指向一个在堆上分配的 vector。 内存管理:这种方式需要手动管理内存,因为数组中的每个 vector 指针都需要适当地构造和析构。 性能问题:每次访问 var2[i][j] 时,实际上涉及到两次内存访问:一次是从数组中获取指针,另一次是从 vector 中访问数据。
参考 #
C++学习之智能指针中的unique_ptr与shared_ptr_C 语言_脚本之家 (jb51.net)
堆栈(Stack)和堆(Heap) #
内存分配 #
程序的内存布局和组织可能会根据所使用的操作系统和体系结构而有所不同。然而,一般来说,内存可以分为以下几个部分:
- 全局段( Global segment ):负责存储全局变量和静态变量,这些变量的生命周期等于程序执行的整个持续时间。
- 代码段( Code segment ):也称为文本段,包含组成我们程序的实际机器代码或指令,包括函数和方法。
- 堆栈( Stack ):用于管理局部变量、函数参数和控制信息(例如返回地址)
- 堆( Heap ):提供了一个灵活的区域来存储大型数据结构和具有动态生命周期的对象。堆内存可以在程序执行期间分配或释放
注意:值得注意的是,内存分配上下文中的堆栈和堆不应与数据结构堆栈和堆混淆,它们具有不同的用途和功能。
堆栈(Stack) #
堆栈简称为栈。
堆栈存储器的主要特点 #
固定大小: 当涉及到堆栈内存时,其大小保持固定,并在程序执行开始时确定。
速度优势: 堆栈内存帧是连续的。因此,在堆栈内存中分配和释放内存的速度非常快。这是通过操作系统管理的堆栈指针对引用进行简单调整来完成的。
控制信息和变量的存储: 堆栈内存负责容纳控制信息、局部变量和函数参数,包括返回地址。
有限的可访问性: 请务必记住,存储在堆栈内存中的数据只能在活动函数调用期间访问。
自动管理: 堆栈内存的高效管理由系统本身完成,不需要我们额外的工作。
举例 #

堆栈段为空
1共 9 个

为主函数创建一个新的堆栈帧
2共 9 个

在 main 函数的堆栈帧中,局部变量 x 现在的值为 5
3共 9 个

调用 add 函数,实际参数为 (5, 10)
4共 9 个

控制权转移到 add 函数,为 add 函数创建一个新的堆栈帧,其中包含局部变量 a、b 和 sum
5共 9 个

add 函数的堆栈帧上的 sum 变量被分配 a + b 的结果
6共 9 个

add 函数完成其任务并且其堆栈帧被销毁
7共 9 个

具有可变结果的主函数的堆栈帧存储从 add 函数返回的值
8共 9 个

在显示结果值(此处未显示)后,主功能块也被销毁,并且堆栈段再次为空
堆(Heap) #
也称为动态内存
是内存分配的野孩子。程序员必须手动管理它。堆内存允许我们在程序执行期间随时分配和释放内存。它非常适合存储大型数据结构或大小事先未知的对象。
举例 #

栈段和堆段为空
1共 7 个

为主函数创建一个新的堆栈帧
2共 7 个

局部变量值被赋予值 42
3共 7 个

在堆上分配了一个指针变量ptr,指针ptr中存放的是分配的堆内存的地址(即0x1000)!
4共 7 个

value变量中存储的值(即42)被赋值给ptr指向的内存位置(堆地址0x1000)
5共 7 个

堆上地址 0x1000 处分配的内存被释放
6共 7 个

main函数的栈帧从栈中弹出(显示result的值后),栈段和堆段再次清空
7共7 个
- 第 3 行: main 调用该函数,并为其创建一个新的堆栈帧。
- 第 5 行: 堆栈帧上的局部变量 value 被赋值为 42 。
- 第 8 行: ptr 使用关键字为堆上的单个整数动态创建的内存分配给指针变量 new 。我们假设堆上新内存的地址为 0x1000。分配的堆内存的地址(0x1000)存储在指针中。 ptr 。
- 第 11 行: 将整数值 42 分配给 ptr (堆地址 0x1000)所指向的内存位置。
- 第 12 行:( ptr )指向的内存位置存储的值 42 被打印到控制台。
- 第 15 行: 使用关键字释放在堆上地址 0x1000 处分配的内存 delete 。在此行之后, ptr 成为悬空指针,因为它仍然保存地址 0x1000,但该内存已被释放。然而,对于这个重要的讨论,我们不会详细讨论悬空指针。
- 第17行: main函数返回0,表示执行成功。
- 第 18 行: 从堆栈中弹出主函数的堆栈帧,并释放所有局部变量 ( value 和)。 ptr
注意:C++ 标准库还提供了一系列智能指针,可以帮助自动化堆中内存分配和释放的过程。
特征 #
- 大小的灵活性: 堆内存大小可以在程序执行过程中发生变化。
- 速度权衡: 在堆中分配和释放内存速度较慢,因为它涉及寻找合适的内存帧和处理碎片。
- 动态对象的存储: 堆内存存储具有动态生命周期的对象和数据结构,如 new Java 或 C++ 中使用关键字创建的对象和数据结构。
- 持久数据: 存储在堆内存中的数据将一直保留在那里,直到我们手动释放它或程序结束。
- 手动管理: 在某些编程语言(例如C和C++)中,必须手动管理堆内存。如果处理不当,可能会导致内存泄漏或资源使用效率低下。
对比 #
- 大小管理: 堆栈内存具有在程序执行开始时确定的固定大小,而堆内存是灵活的,可以在程序的整个生命周期中更改。
- 速度: 堆栈内存在分配和释放内存时具有速度优势,因为它只需要调整引用。相反,由于需要定位合适的内存帧并管理碎片,堆内存操作速度较慢。
- 存储目的: 堆栈内存指定用于控制信息(例如函数调用和返回地址)、局部变量和函数参数(包括返回地址)。另一方面,堆内存用于存储具有动态生命周期的对象和数据结构,例如 new Java 或 C++ 中使用关键字创建的对象和数据结构。
- 数据可访问性: 堆栈内存中的数据只能在活动函数调用期间访问,而堆内存中的数据在手动释放或程序结束之前仍然可以访问。
- 内存管理: 系统自动管理堆栈内存,优化其使用,以实现快速高效的内存引用。相比之下,堆内存管理是程序员的责任,处理不当可能会导致内存泄漏或资源使用效率低下。
数据结构 #
堆栈(Stack) #
堆栈简称为栈。一种线性表数据结构,是一种只允许在表的一端进行插入和删除操作的线性表
- 我们把栈中允许插入和删除的一端称为 「栈顶(top)」;另一端则称为 「栈底(bottom)」。
- 表中没有任何数据元素时,称之为 「空栈」。
- 栈的插入操作又称为「入栈」或者「进栈」
- 栈的删除操作又称为「出栈」或者「退栈」。
- 栈是一种 「后进先出(Last In First Out)」 的线性表,简称为 「LIFO 结构」。
堆栈的基本操作 #
初始化空栈:创建一个空栈,定义栈的大小 size,以及栈顶元素指针 top。
判断栈是否为空:当堆栈为空时,返回 True。当堆栈不为空时,返回 False。一般只用于栈中删除操作和获取当前栈顶元素操作中。
判断栈是否已满:当堆栈已满时,返回 True,当堆栈未满时,返回 False。一般只用于顺序栈中插入元素和获取当前栈顶元素操作中。
插入元素(进栈、入栈):相当于在线性表最后元素后面插入一个新的数据元素。并改变栈顶指针 top 的指向位置。
删除元素(出栈、退栈):相当于在线性表最后元素后面删除最后一个数据元素。并改变栈顶指针 top 的指向位置。
获取栈顶元素:相当于获取线性表中最后一个数据元素。与插入元素、删除元素不同的是,该操作并不改变栈顶指针 top 的指向位置。
堆(Heap) #
参考 #
堆栈与堆(Stack vs Heap):有什么区别?图文并茂拆解代码解析!_内存_存储_函数 (sohu.com)
静态和动态链接 #
编译分三步:
- 预处理(宏、#include、预编译指令#ifdef等)生成.i文件
- 编译,生成.s汇编文件
- 汇编,将汇编语言翻译为二进制机器语言
静态链接和动态链接两者最大的区别就在于链接的时机不一样,静态链接是在形成可执行程序前,而动态链接的进行则是在程序执行时,下面来详细介绍这两种链接方式。
静态链接 #
原理 #
将所有.c/cpp文件独立编译生成的.o进行链接从而形成可执行程序
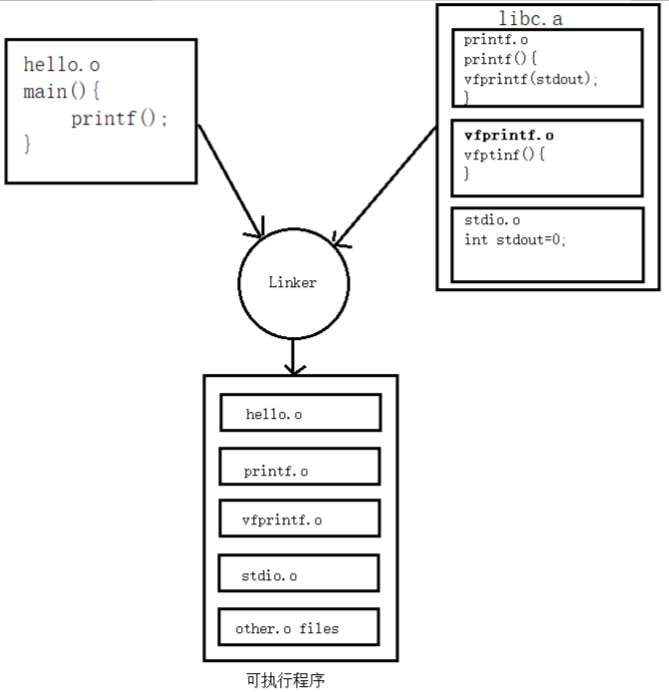
我们知道,链接器在链接静态链接库的时候是以目标文件为单位的。比如我们引用了静态库中的printf()函数,那么链接器就会把库中包含printf()函数的那个目标文件链接进来,如果很多函数都放在一个目标文件中,很可能很多没用的函数都被一起链接进了输出结果中。由于运行库有成百上千个函数,数量非常庞大,每个函数独立地放在一个目标文件中可以尽量减少空间的浪费,那些没有被用到的目标文件就不要链接到最终的输出文件中。
优缺点 #
浪费空间
另一方面就是更新比较困难,因为每当库函数的代码修改了,这个时候就需要重新进行编译链接形成可执行程序。
在可执行程序中已经具备了所有执行程序所需要的任何东西,在执行的时候运行速度快。
动态链接 #
将程序按照模块拆分成各个相对独立的部分,程序运行到时才链接
假设现在有两个程序program1.o和program2.0,这两者共用同一个库lib.o,假设首先运行程序program1,系统首先加载program1.0,当系统发现program1.o中用到了lib.0,即program1.o依赖于lib.o,那么系统接着加载lib.o,如果program1.o和lib.o还依赖于其他目标文件,则依次全部加载到内存中。当program2运行时,同样的加载program2.0,然后发现program2.o依赖于lib.o,但是此时lib.o已经存在于内存中,这个时候就不再进行重新加载,而是将内存中已经存在的lib.o映射到program2的虚拟地址空间中,从而进行链接(这个链接过程和静态链接类似)形成可执行程序。
动态链接的优点显而易见,就是即使需要每个程序都依赖同一个库,但是该库不会像静态链接那样在内存中存在多分,副本,而是这多个程序在执行时共享同一份副本;另一个优点是,更新也比较方便,更新时只需要替换原来的目标文件,而无需将所有的程序再重新链接一遍。当程序下一次运行时,新版本的目标文件会被自动加载到内存并且链接起来,程序就完成了升级的目标。但是动态链接也是有缺点的,因为把链接推迟到了程序运行时,所以每次执行程序都需要进行链接,所以性能会有一定损失。
据估算,动态链接和静态链接相比,性能损失大约在5%以下。经过实践证明,这点性能损失用来换区程序在空间上的节省和程序构建和升级时的灵活性是值得的。
参考 #
多线程 #
- C++11及以后标准才有
进程与线程的区别 #
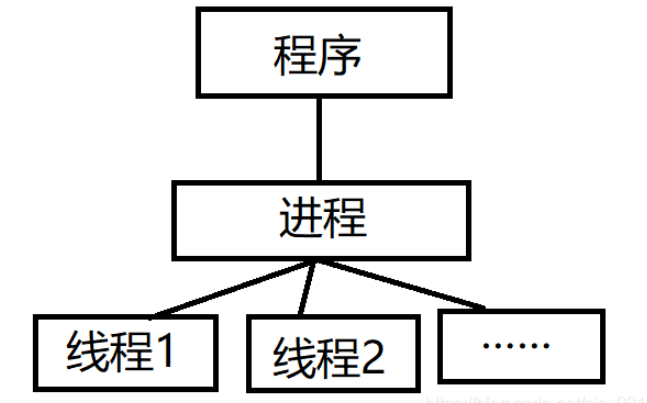
进程是正在运行的程序的实例,是可以执行的程序或文件(例如: exe);而线程是是进程中的实际运作单位,指的是进程的指定单元,也叫执行路径
一个程序有且只有一个进程,但可以拥有至少一个的线程
不同进程拥有不同的地址空间,互不相关,而不同线程共同拥有相同进程的地址空间
线程是CPU调度和分配的基本单位,可以理解为CPU只看得到线程;进程是操作系统进行资源分配的最小单位
当你执行这个程序时,CPU响应为该进程分配资源对其进行处理,但是CPU看不到"进程", 看到的是由很多个线程组成的一个网络(就是一个进程),于是CPU开始为这些线程利用
时间分配算法来循环执行任务。
# ubuntu下查看电脑CPU核数,CPU个数,最大线程数(逻辑CPU的数量)
## CPU个数
more /proc/cpuinfo |grep "physical id"|uniq|wc -l # 1
## 查看CPU核数
cat /proc/cpuinfo| grep "cpu cores"| uniq # 6
## 查看最大线程数(逻辑CPU的数量)
more /proc/cpuinfo |grep "physical id"|grep "0"|wc -l # 12
并发和并行 #
并发: 指的是两个(或以上)的线程同时请求执行,但是同一瞬间CPU只能执行一个,于是CPU就安排他们交替执行,我们看起来好像是同时执行的,其实不是。并发可认为是一种逻辑结构的设计模式。你可以用并发的设计方式去设计模型,然后运行在一个单核系统上,通过系统动态地逻辑切换制造出并行的假象。
并发在生活中随处可见,单核CPU边听歌边写代码
并行: 指的是两个(或以上)的线程同时执行。
特点 #
- 线程是在thread对象被定义的时候开始执行的,而不是在调用join函数时才执行的,调用join函数只是阻塞等待线程结束并回收资源
- 线程会在函数运行完毕后自动释放,不推荐利用其他方法强制结束线程,可能会因资源未释放而导致内存泄漏。
- 没有执行
join或detach的线程在程序结束时会引发异常
std::thread性能分析 #
在C++中,std::thread(标准线程)的性能主要受以下几个因素影响:
- 线程创建和销毁的开销(Overhead of Thread Creation and Destruction):每次创建或销毁线程都会带来一定的开销。这是因为操作系统需要为每个线程分配和回收资源,如栈空间、线程局部存储等。因此,频繁地创建和销毁线程可能会导致性能下降。
- 线程切换的开销(Overhead of Thread Switching):操作系统通过线程调度器来管理多个线程的执行。当一个线程的执行被暂停,另一个线程被唤醒时,就会发生线程切换。线程切换会带来一定的开销,因为需要保存和恢复线程的执行环境。
- 线程同步的开销(Overhead of Thread Synchronization):在多线程环境中,通常需要使用同步机制(如互斥锁、条件变量等)来协调线程的执行。这些同步操作也会带来一定的开销。
为了减少这些开销,我们可以采取以下策略:
- 线程池(Thread Pool):通过预先创建一定数量的线程,并重复使用这些线程,可以减少线程创建和销毁的开销。
- 减少线程切换(Reduce Thread Switching):通过合理地设计程序,减少不必要的线程切换,可以提高性能。
- 减少锁的使用(Reduce Lock Usage):通过使用无锁数据结构或者减少锁的粒度,可以减少线程同步的开销。
多线程真的能加速? #
线程的调度是根据cpu的算法,如果线程的运算量不大,cpu 算法调度线程不一定会平均分配给每个内核的
测试代码创建了四个线程,四个线程都遍历一百万次。通过使用JDK自带监控工具:Visual VM 查看线程的执行过程
public class ThreadTest { private static final int num = 1000 * 1000; public static void main(String[] args) throws InterruptedException { new Thread(()->{ for (int i = 0; i < num; i++) { System.out.println(i); } },"线程1").start(); new Thread(()->{ for (int i = 0; i < num; i++) { System.out.println(i); } },"线程2").start(); new Thread(()->{ for (int i = 0; i < num; i++) { System.out.println(i); } },"线程3").start(); new Thread(()->{ for (int i = 0; i < num; i++) { System.out.println(i); } },"线程4").start(); } }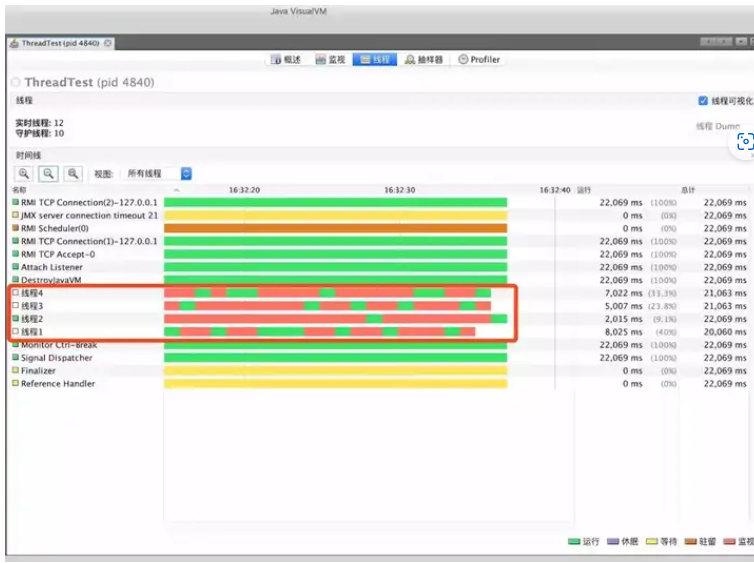
发现,多个线程根本没有并发执行,而是不断的在线程之间 上下文切换!也就是说,4个线程都是在单个内核执行,其他的内核并没有工作
this_thread #

#include <iostream>
#include <thread>
#include <atomic>
using namespace std;
atomic_bool ready = 0;
// uintmax_t ==> unsigned long long
void sleep(uintmax_t ms) {
this_thread::sleep_for(chrono::milliseconds(ms));
}
void count() {
while (!ready) this_thread::yield();
for (int i = 0; i <= 20'0000'0000; i++);
cout << "Thread " << this_thread::get_id() << " finished!" << endl;
return;
}
int main() {
thread th[10];
for (int i = 0; i < 10; i++)
th[i] = thread(::count);
sleep(5000);
ready = true;
cout << "Start!" << endl;
for (int i = 0; i < 10; i++)
th[i].join();
return 0;
}
多个线程操作同一个变量 #
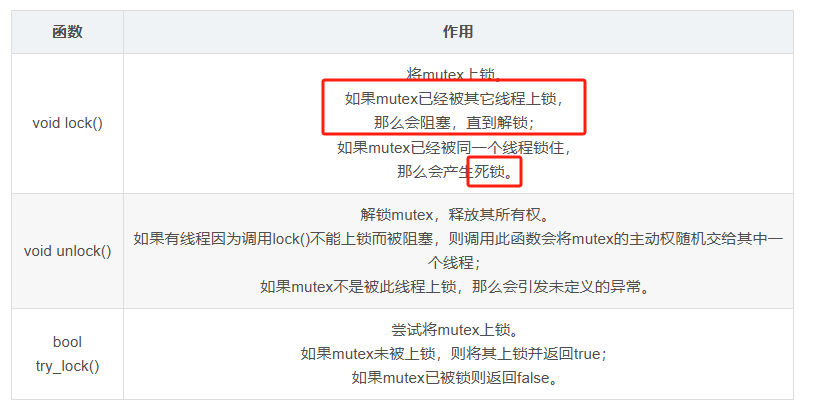
std::mutex
一个线程将mutex锁住时,其它的线程就不能操作mutex,直到这个线程将mutex解锁
mutex很好地解决了多线程资源争抢的问题,但它也有缺点:太……慢……了……
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
int n = 0;
mutex mtx;
void count10000() {
for (int i = 1; i <= 10000; i++) {
mtx.lock();
n++;
mtx.unlock(); //去掉mtx,输出的n就不正确了
}
}
int main() {
thread th[100];
for (thread &x : th)
x = thread(count10000);
for (thread &x : th)
x.join();
cout << n << endl;
return 0;
}
std::atomic
比mutex快
std::atomic_int只是std::atomic<int>的别名
#include <iostream>
#include <thread>
// #include <mutex> //这个例子不需要mutex了
#include <atomic>
using namespace std;
atomic_int n = 0;
void count10000() {
for (int i = 1; i <= 10000; i++) {
n++;
}
}
int main() {
thread th[100];
for (thread &x : th)
x = thread(count10000);
for (thread &x : th)
x.join();
cout << n << endl;
return 0;
}
async #
大多数情况下使用async而不用thread #
async可以根据情况选择同步执行或创建新线程来异步执行,当然也可以手动选择。对于async的返回值操作也比thread更加方便。
注:std::async定义在
future头文件中。
api #


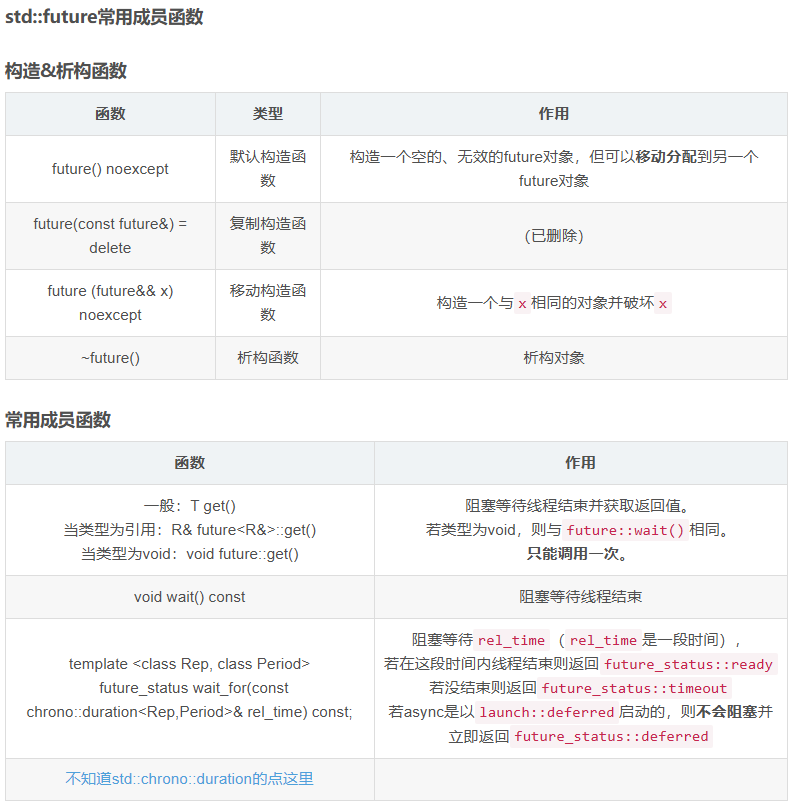
举例 #
使用std::future获取线程的返回值 #
定义了一个对象val,它的类型是std::future<int>,这里的int代表这个函数的返回值是int类型。在创建线程后,我们使用了future::get()来阻塞等待线程结束并获取其返回值
// Compiler: MSVC 19.29.30038.1
// C++ Standard: C++17
#include <iostream>
// #include <thread> // 这里我们用async创建线程
#include <future> // std::async std::future
using namespace std;
template<class ... Args> decltype(auto) sum(Args&&... args) {
// C++17折叠表达式
// "0 +"避免空参数包错误
return (0 + ... + args);
}
int main() {
// 注:这里不能只写函数名sum,必须带模板参数
future<int> val = async(launch::async, sum<int, int, int>, 1, 10, 100);
// future::get() 阻塞等待线程结束并获得返回值
cout << val.get() << endl;
return 0;
}
Out: 111
void特化std::future #
// Compiler: MSVC 19.29.30038.1
// C++ Standard: C++17
#include <iostream>
#include <future>
using namespace std;
void count_big_number() {
// C++14标准中,可以在数字中间加上单
// 引号 ' 来分隔数字,使其可读性更强
for (int i = 0; i <= 10'0000'0000; i++);
}
int main() {
future<void> fut = async(launch::async, count_big_number);
cout << "Please wait" << flush;
// 每次等待1秒
while (fut.wait_for(chrono::seconds(1)) != future_status::ready)
cout << '.' << flush;
cout << endl << "Finished!" << endl;
return 0;
}
如果你运行一下这个代码,你也许就能搞懂那些软件的加载画面是怎么实现的。
多线程与核心 #
# ubuntu下查看电脑CPU核数,CPU个数,最大线程数(逻辑CPU的数量)
## CPU个数
more /proc/cpuinfo |grep "physical id"|uniq|wc -l # 1
## 查看CPU核数
cat /proc/cpuinfo| grep "cpu cores"| uniq # 6
## 查看最大线程数(逻辑CPU的数量)
more /proc/cpuinfo |grep "physical id"|grep "0"|wc -l # 12
speedup #
分析工具 #
总结 #
- 使用const
- 使用inline
- 避免频繁的内存分配和释放:使用对象池技术预先分配对象?
- 使用引用传递而非指针传递:在某些情况下,使用引用可以避免对象的复制,提高性能
- 减少函数调用次数
- 使用位运算替代算术运算:在低级代码中,位运算通常比算术运算更快
- 使用编译器优化选项:如
-O2或-O3,让编译器进行更多的优化 - 选择合适的数据结构:例如,使用
std::vector而不是std::list可以提高内存局部性,减少访问时间 - 优化算法:选择高效的算法和数据结构,如使用哈希表进行快速查找
- 使用
std::move进行容器转移:移动语义可以避免不必要的复制,提高效率? - 使用局部静态变量和成员变量
- 使用作用域限定:限定变量的作用域,避免不必要的变量生命周期延长
- 预先使用
reserve优化容器:减少动态数组类型的容器在运行时的内存分配次数? - 减少除法运算:将除法运算转换为乘法运算,以提高效率?
- 使用多线程:对于可以并行处理的任务,使用多线程可以显著提高性能
- 减少值传递,多用引用传递:避免在函数调用时复制整个对象,特别是对于大型对象
- 避免不同数据类型相互操作:减少数据类型转换,以提高效率
- 使用内存访问优化:例如,使用指针直接访问数组元素,而不是使用
.at()方法 - 直接使用现有的封装函数很方便,但是效率不是最好的,简单的功能实现,最好还是自己写源码
Boost #
简介 #
Boost是一个流行的、开源的C++库集合,提供了各种功能强大的库和工具,扩展了C++语言的能力,并为开发者提供了更高级别的抽象和工具。Boost库经过广泛的使用和测试,被认为是C++社区的事实标准之一
Boost库包含了多个模块,每个模块都提供了不同领域的功能和工具,覆盖了诸如字符串操作、数据结构、算法、日期时间处理、文件系统、线程、网络、正则表达式等各个方面。以下是一些常用的Boost库:
1.Boost.Asio:提供了异步I/O操作的网络编程库,支持TCP、UDP、串口等网络协议。
2.Boost.Smart_Ptr:提供了智能指针类,如shared_ptr和weak_ptr,用于方便地进行内存管理。
3.Boost.Filesystem:提供了对文件系统的访问和操作,包括文件和目录的创建、删除、遍历等。
4.Boost.Regex:提供了正则表达式的功能,用于进行文本匹配和搜索操作。
5.Boost.Thread:提供了跨平台的多线程编程接口,简化了线程的创建、同步和通信等操作。
6.Boost.Serialization:提供了对象的序列化和反序列化功能,可以将对象以二进制或XML格式进行存储和传输。
7.Boost.Math用于数学计算
8.Boost.Graph用于图论算法 Chapter 31. Boost.Graph
9.Boost.Algorithm - 提供了包括排序、搜索等在内的各种算法。
10.Boost.Numeric - 提供了用于数值计算的库,如用于线性代数、随机数生成等
参考 #
- 【C++】开源:Boost库常用组件配置使用-腾讯云开发者社区-腾讯云
- 项目Github地址:
https://github.com/boostorg/boost - Boost库在线书籍:
https://wizardforcel.gitbooks.io/the-boost-cpp-libraries/content/0.html - 官方文档:The Boost C++ Libraries
ODB #
ODB(Object-Relational Mapping)是一个C++库,用于将C++对象映射到关系数据库中。
buglist #
#include <iostream>
#include <vector>
#include <array>
using namespace std;
int main()
{
int a = 10;
int b = 3;
const size_t wire_max_level = a;
const size_t wire_max_sublevel = b;
array<array<vector<array<int, 2>>, wire_max_level>, wire_max_sublevel> dst;
}
SystemC #
环境配置 #
EDA Playground #
Local #
SystemC 学习之 Linux 安装 SystemC(一)_systemc如何安装-CSDN博客
other #
Complexity #
Time Complexity #
算法运行所花费的时间量化为与输入长度有关的函数
随着输入的量级增加,低阶项相对无关紧要,因此仅采用最高阶项
举例 #
假设给定数组array A,在array A中找出是否存在一组pair(x,y)使其和为x+y=z,array A中有N个元素
for(int i = 0;i < n;i++)
for(int j = 0;j < n;j++)
if(i!=j && a[i]+a[j] == z)
return true
return false
分析算法的时候通常考虑最差的情况,也就是说上面算法的时间复杂度为O(N2)
count = 0
i = N
while(i > 0):
for j in range(i):
count+=1
i /= 2
count+=1总共运行次数为N + N/2 + N/4+…+1= 2 * N,因此时间复杂度为O(N)
Space Complexity #
算法运行所占用的空间量化为与输入长度有关的函数
复杂度分类 #

P问题(Polynomial Time) #
可以在确定性多项式时间内解决的决策问题集合
常见P问题有计算最大公约数;寻找最大匹配(maximum matching);线性规划的决策版本
NP问题(Non-deterministic Polynomial Time) #
NP问题是机器可以在非确定性多项式时间内解决的决策问题的集合
常见NP问题有布尔可满足性问题 (Boolean Satisfiability Problem SAT),哈密顿路径问题,图着色问题
NP-hard问题 #
NP-hard问题至少要和NP问题中最难的一类一样难,代表所有NP问题都能在多项式时间复杂度内归约(reduction)到的问题
归约:我们现在遇到了个问题,可以把它转化到一个某个已解决的问题上,而不是一定要直接解决这个问题。
如果给出了一个NP-hard 问题的解,验证也需要很长时间
常见的NP-hard问题有停机问题(Halting problem),TSP
NP-complete问题 #
如果一个问题既是 NP 问题又是 NP-hard问题,那么它就是NP-complete问题
NP-complete问题是 NP 中的难题。
常见NP-complete问题有0/1背包问题,哈密尔顿回路,顶点覆盖(Vertex cover)
参考 #
时间和空间复杂度及复杂度分类(P,NP,NP-hard,NP-complete)_np-hard np-complete-CSDN博客
Python #
print #
print(f" pin:{self.connecting_pins[0]}")
class #
basic #
class PIN:
def __init__(self, value_=PIN_VALUE_X):
self.value = value_
def func0(self):
...
def __str__(self):
return f"value={self.value}\n"
reset #
def __init__(self, ...)
super().__init__()
...
self.reset()#调用的是当前类中的 reset 方法。这个方法通常用于重置对象的状态到初始状态。
__init__.py
#
- 包初始化:当一个目录包含
__init__.py文件时,Python 解释器会将其视为一个包,允许你使用import语句导入该目录下的模块。 - 初始化代码:
__init__.py文件可以包含包的初始化代码。这些代码在包被导入时执行,可以用来执行一些初始化操作,比如设置包的属性、定义函数或类等。 - 命名空间管理:
__init__.py文件允许你控制包的命名空间。你可以通过这个文件来定义哪些模块或对象应该被暴露给包的使用者。 - 避免命名冲突:如果你的包中包含的模块名与标准库或其他第三方库的模块名相同,通过在
__init__.py中明确导入和导出特定的模块或对象,可以避免命名冲突。 - 向后兼容性:在 Python 3.3 之前,
__init__.py文件是必须的,以将目录标记为包。从 Python 3.3 开始,PEP 420 允许隐式命名空间包,这意味着即使没有__init__.py文件,也可以将目录作为包使用。但是,使用__init__.py仍然是一种良好的实践,因为它提供了上述的好处。 - 运行包:如果
__init__.py文件中包含if __name__ == "__main__":块,那么当包作为脚本直接运行时,该块中的代码将被执行。
mypackage/
│
├── __init__.py
├── module1.py
└── module2.py
# mypackage/__init__.py
from .module1 import my_function
from .module2 import MyClass
import mypackage
mypackage.my_function()
mypackage.MyClass()
*args 和 **kwds
#
def func(*args, **kwds):
for arg in args:
print(arg)
for key, value in kwds.items():
print(f"{key} = {value}")
func(1, 2, 3, a=4, b=5) # 输出:
# 1
# 2
# 3
# a = 4
# b = 5
Pytorch #
ema #
指数加权移动平均(Exponential Moving Average, EMA)是一种用于平滑时间序列数据的技术,它通过对历史数据赋予不同的权重来实现平滑。与简单移动平均(SMA)不同,EMA对最近的数据赋予更大的权重,从而能够更敏感地反映数据的近期变化趋势

class ExponentialMovingAverage(torch.optim.swa_utils.AveragedModel):
"""Maintains moving averages of model parameters using an exponential decay.
``ema_avg = decay * avg_model_param + (1 - decay) * model_param``
`torch.optim.swa_utils.AveragedModel <https://pytorch.org/docs/stable/optim.html#custom-averaging-strategies>`_
is used to compute the EMA.
"""
def __init__(self, model, decay, device):
def ema_avg(avg_model_param, model_param, num_averaged):
return decay * avg_model_param + (1 - decay) * model_param
super().__init__(model, device, ema_avg)
DGL #
with g.local_scope(): #
Tensorflow #
基本操作 #
pytorch函数mm() mul() matmul()区别_torch.mm matmul区别-CSDN博客
tf.Variable(initial_value=1.)
tf.constant([[1., 2.], [3., 4.]])
tf.zero
tf.square() 操作代表对输入张量的每一个元素求平方
tf.reduce_sum() 操作代表对输入张量的所有元素求和
tf.random.uniform
print(A.shape) # 输出(2, 2),即矩阵的长和宽均为2
print(A.dtype) # 输出<dtype: 'float32'>
print(A.numpy())
自动求导 #
import tensorflow as tf
x = tf.Variable(initial_value=3.)
with tf.GradientTape() as tape: # 在 tf.GradientTape() 的上下文内,所有计算步骤都会被记录以用于求导
y = tf.square(x)
y_grad = tape.gradient(y, x) # 计算y关于x的导数
print(y, y_grad)
tf.GradientTape() 是一个自动求导的记录器。只要进入了 with tf.GradientTape() as tape 的上下文环境,则在该环境中计算步骤都会被自动记录。比如在上面的示例中,计算步骤 y = tf.square(x) 即被自动记录。离开上下文环境后,记录将停止,但记录器 tape 依然可用,因此可以通过 y_grad = tape.gradient(y, x) 求张量 y 对变量 x 的导数。
X = tf.constant([[1., 2.], [3., 4.]])
y = tf.constant([[1.], [2.]])
w = tf.Variable(initial_value=[[1.], [2.]])
b = tf.Variable(initial_value=1.)
with tf.GradientTape() as tape:
L = tf.reduce_sum(tf.square(tf.matmul(X, w) + b - y))
w_grad, b_grad = tape.gradient(L, [w, b]) # 计算L(w, b)关于w, b的偏导数
print(L, w_grad, b_grad)
模型与层 #
简单粗暴 TensorFlow 2 | A Concise Handbook of TensorFlow 2 — 简单粗暴 TensorFlow 2 0.4 beta 文档 (tf.wiki)
Keras 在
tf.keras.layers下内置了深度学习中大量常用的的预定义层,同时也允许我们自定义层keras.layers.Dense
units:输出张量的维度;activation:激活函数,对应于 ,默认为无激活函数(
,默认为无激活函数( a(x) = x)。常用的激活函数包括tf.nn.relu、tf.nn.tanh和tf.nn.sigmoid;use_bias:是否加入偏置向量bias,即 。默认为
。默认为 True;kernel_initializer、bias_initializer:权重矩阵kernel和偏置向量bias两个变量的初始化器。默认为tf.glorot_uniform_initializer1 。设置为tf.zeros_initializer表示将两个变量均初始化为全 0;- 该层包含权重矩阵
kernel = [input_dim, units]和偏置向量bias = [units]2 两个可训练变量
tf.keras.layers.Conv2D
tf.keras.layers.MaxPool2D
tf.keras.layers.Reshape
tf.keras.layers.LSTMCell
我们可以通过继承
tf.keras.Model这个 Python 类来定义自己的模型在继承类中,我们需要重写
__init__()(构造函数,初始化)和call(input)(模型调用)两个方法,同时也可以根据需要增加自定义的方法。实例化类
model = Model()后,可以通过model.variables这一属性直接获得模型中的所有变量
自定义层 #
tf.keras.models.Sequential() 提供一个层的列表,就能快速地建立一个 tf.keras.Model 模型并返回
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(100, activation=tf.nn.relu),
tf.keras.layers.Dense(10),
tf.keras.layers.Softmax()
])
变量的恢复和保存 #
TensorFlow常用模块 — 简单粗暴 TensorFlow 2 0.4 beta 文档 (tf.wiki)
训练过程可视化 #
GPU使用 #
分布式训练 #
TPU训练 #
install #
使用 pip 安装 TensorFlow (google.cn)
TensorFlow安装与环境配置 — 简单粗暴 TensorFlow 2 0.4 beta 文档 (tf.wiki)
#需要使用 Python 3.6-3.9 和 pip 19.0 及更高版本
sudo apt update
sudo apt install python3-dev python3-pip python3-venv
python3 --version
pip3 --version
#enter vir env
#从 TensorFlow 2.1 开始,pip 包 tensorflow 即同时包含 GPU 支持,无需通过特定的 pip 包 tensorflow-gpu 安装 GPU 版本
pip install --upgrade tensorflow#install
#指定版本号
pip install tensorflow==2.6.0
reference #
简单粗暴 TensorFlow 2 | A Concise Handbook of TensorFlow 2 — 简单粗暴 TensorFlow 2 0.4 beta 文档 (tf.wiki)
collections #
defaultdict #
from collections import defaultdict
# 创建一个默认值为int的defaultdict,int类型的默认值为0
dd = defaultdict(int)
# 访问一个不存在的键,会自动创建该键,并将值设置为默认值0
print(dd['foo']) # 输出: 0
# 手动设置一个键的值
dd['foo'] = 1
# 再次访问该键,返回设置后的值
print(dd['foo']) # 输出: 1
NameTuple #
元组 tuple 一样,NamedTuple 也是不可变数据类型,创建之后就不能改变内容
NamedTuple 不像数组那样使用下标读写,反而和类相似,使用 . 来读写。
collections.namedtuple(typename, field_names, *, rename=False, defaults=None, module=None)

# 导包
from collections import namedtuple
# 创建普通元组
point = (22, 33)
print(point) # 输出:(22, 33)
# 创建命名元组
Point = namedtuple('Point', 'x y')#我们先用 namedtuple 创建了一个名为 Point,有两个字段 x、y 的子类,然后将这个类赋给 Point 变量。
point_A = Point(22, 33)#相当于 new
print(point_A) # 输出:Point(x=22, y=33)
#三种风格
Point = namedtuple('Point', 'x y')
Point = namedtuple('Point', 'x,y')
Point = namedtuple('Point', ['x', 'y'])
#取值
print(point_A[0])
print(point_A[1])
print(point_A.x)
print(point_A.y)
#创造一个对象
point1 = Point(x=1, y=2)
【Python 高级特性】深入 NamedTuple 命名元组-CSDN博客
map #
map()传入的第一个参数是f,即函数对象本身。由于结果r是一个 Iterator,Iterator是惰性序列,因此通过list()函数让它把整个序列都计算出来并返回一个list。你可能会想,不需要map()函数,写一个循环,也可以计算出结果。但是,map要比循环更快,更稳健。
def Fun(x) : # 计算平方数
return x + 2
data = [1, 4, 9, 16, 25]
outdata = list(map(Fun, data))
#结果:outdata=[3, 4, 6, 7, 10, 12]
#lambda
rewards = list(map(lambda s: s.reward, batch))#get reward from batch
TCL #
基本知识 #
list #
一组单词或者使用双引号或大括号可以用来表示一个简单的列表
#!/usr/bin/tclsh
set myVariable {red green blue}
puts [lindex $myVariable 2]
set myVariable "red green blue"
puts [lindex $myVariable 1]
blue green
关联数组 #
#!/usr/bin/tclsh
set marks(english) 80
puts $marks(english)
set marks(mathematics) 90
puts $marks(mathematics)
80 90
参考 #
CUDA #
简介 #
什么是CUDA #
CUDA建立在NVIDIA的GPU上的一个通用并行计算平台和编程模型
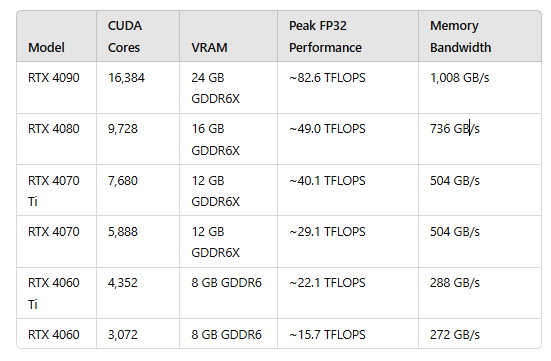
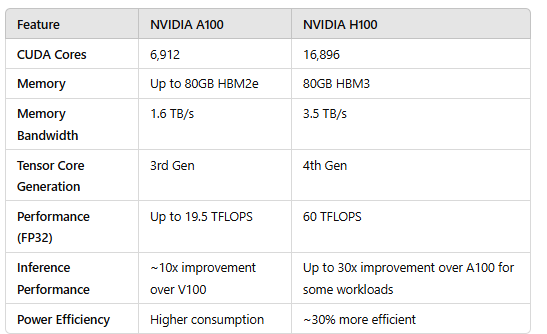
GPU性能指标 #
- 核心数:为GPU提供计算能力的硬件单元,核心数量越多,可并行运算的线程数量也就越多
- GPU显存容量
- GPU计算峰值:代表GPU的最大计算能力
- 显存带宽:运算单元与显存之间的通信速率
下图由GPT生成:
架构 #
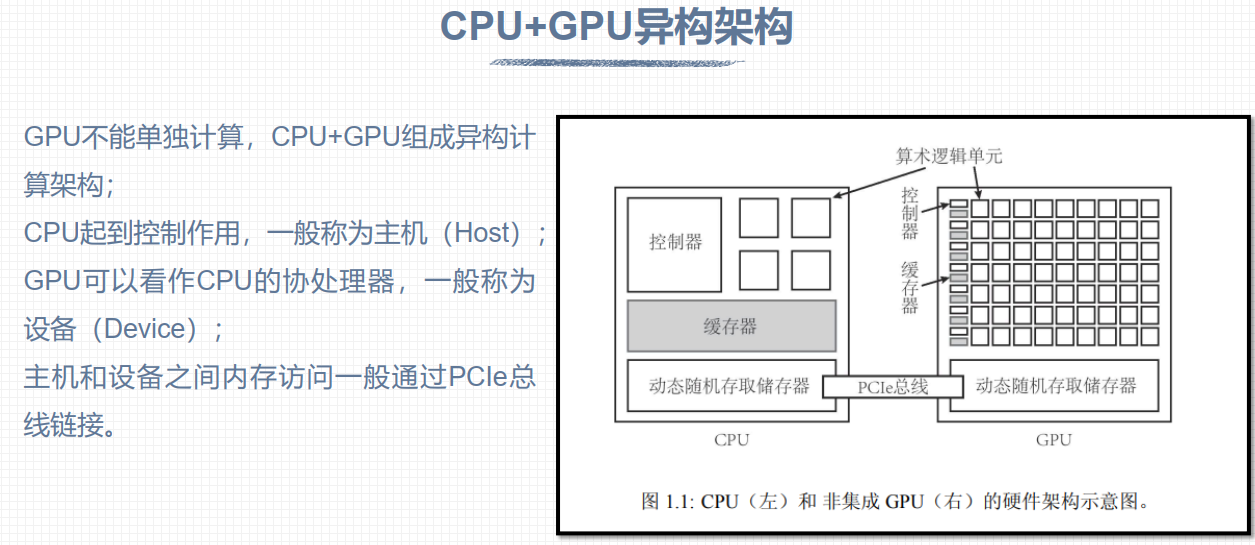
- 控制器:
- 算数逻辑单元
- 缓存器
- 动态随机存取储存器
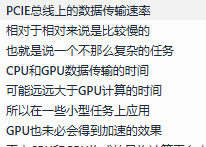
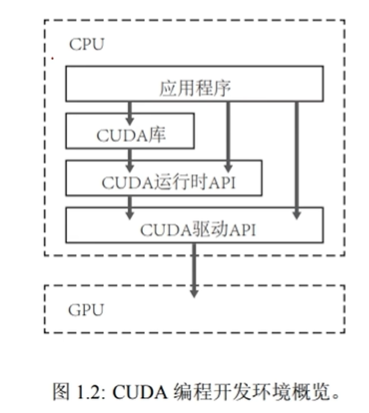
开发环境 #
可以用C++或python

command #
nvidia-smi
显存存满了GPU不一定在高速工作
nvidia-smi -q:显示显卡的详细信息
nvidia-smi -q -i 0:多卡下,看具体是哪一块显卡nvidia-smi -q -i 0 -d MEMORY:具体看MEMORY的信息
basic #
核函数(Kernel function) #
主机对设备的调用是通过核函数进行的
__global__和void的书写和函数是两个重要的规则
- 核函数只能访问GPU内存
- CPU与GPU是无法相互直接访问各自内存的
- 通过PCIE进行相互访问
- 核函数不能使用变长参数
- 核函数不能使用静态变量
- 核函数不能使用函数指针
- 核函数具有异步性
- CPU主机无法控制GPU设备的执行
- CPU主机不会等待核函数执行完毕
- 所以我们需要显示的调用同步函数同步主机CPU
- 核函数不支持C++的iostream, 要使用printf来显示
- 为什么可以使用printf?
- 一个helloworld核函数
//声明
__global__ void hello_from_gpu()
{
printf("Hello World from the the GPU\n");
}
//调用
hello_from_gpu<<<1, 1>>>(); //<<<grid_size, block_size>>>指定线程块和线程数量
同步 #
使用原因:CPU主机不会等待核函数执行完毕
cudaDeviceSynchronize()
线程模型 #
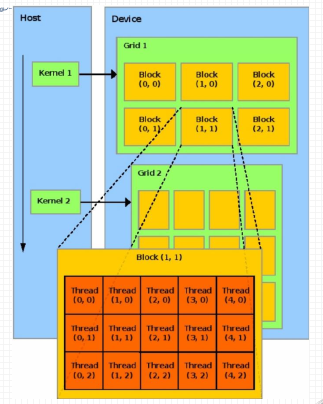
grid->block->thread
- 线程分块是逻辑上的划分, 物理上线程不分块
- 最大允许线程块大小: 1024
- 最大允许网格大小: 231 - 1 (针对一维网格)
一维线程模型 #
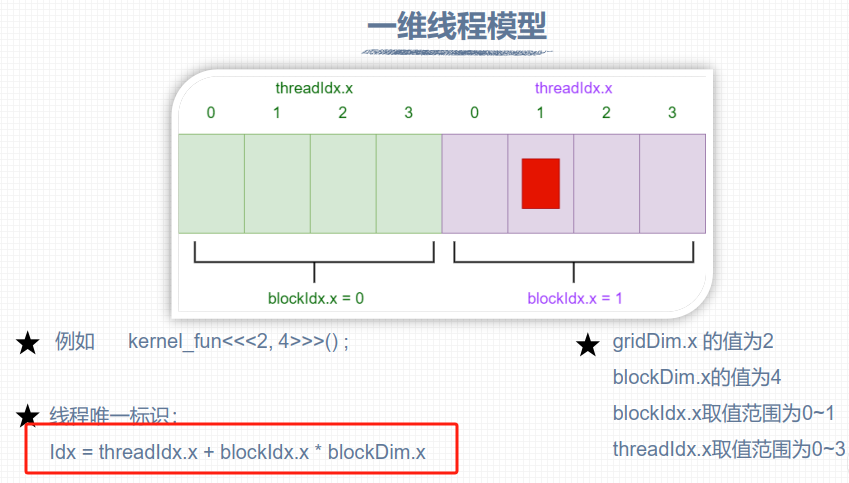
8个线程helloworld #
#include <stdio.h>
__global__ void hello_from_gpu()
{
const int bid = blockIdx.x;
const int tid = threadIdx.x;
const int id = threadIdx.x + blockIdx.x * blockDim.x;
printf("Hello World from block %d and thread %d, global id %d\n", bid, tid, id);
}
int main(void)
{
hello_from_gpu<<<2, 4>>>();
cudaDeviceSynchronize();
return 0;
}
Hello World from block 1 and thread 0, global id 4 Hello World from block 1 and thread 1, global id 5 Hello World from block 1 and thread 2, global id 6 Hello World from block 1 and thread 3, global id 7 Hello World from block 0 and thread 0, global id 0 Hello World from block 0 and thread 1, global id 1 Hello World from block 0 and thread 2, global id 2 Hello World from block 0 and thread 3, global id 3
多维线程模型 #
cuda最多3维度


gridDim和blockDim没有指定的维度默认为1:

线程块总数不能超过1024
线程index计算 #
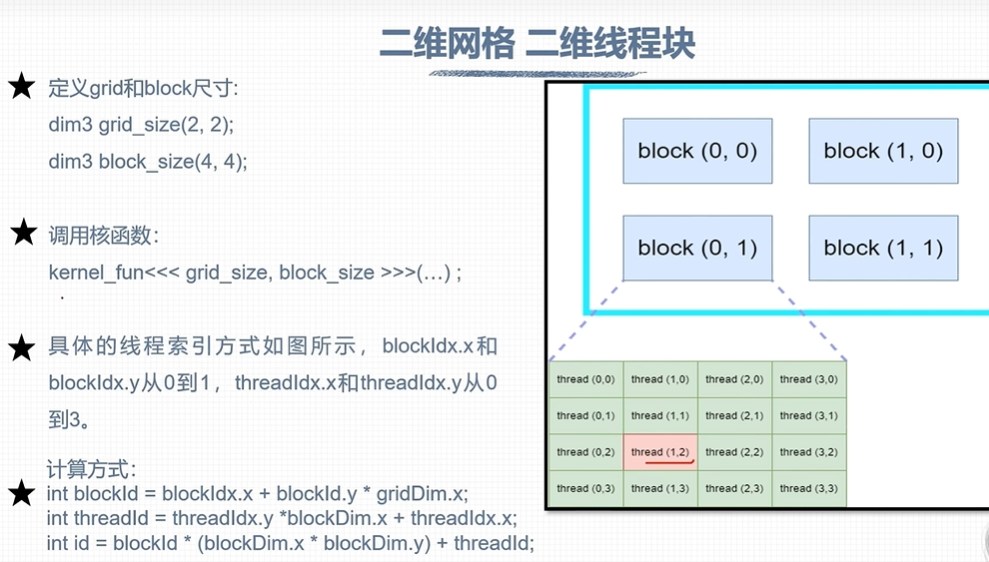


nvcc #
简介 #
类似gcc, 用于编译.cu文件
原理 #
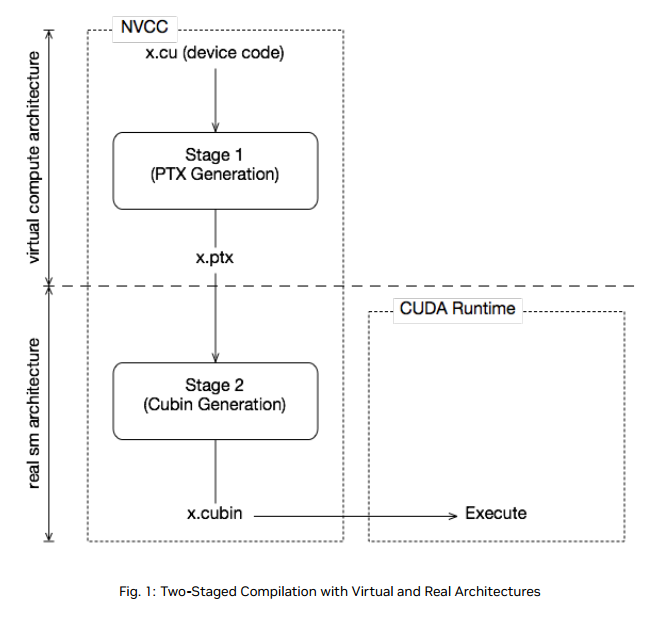
- nvcc分离全部源代码为: (1) 主机代码 (2) 设备代码
- nvcc先将设备代码编译为PTX(Parallel Thread Execution) 伪汇编代码, 再将PTX代码编译为二进制的cubin目标代码
- 在将源代码编译为 PTX 代码时, 需要用选项**-arch=compute_XY指定一个虚拟架构**的计算能力,用以确定代码中能够使用的CUDA功能。
- 在将PTX代码编译为cubin代码时, 需要用选项**-code=sm_XY指定一个真实架构**的计算能力, 用以确定可执行文件能够使用的GPU。
PTX #
- PTX( Parallel Thread Execution) 是CUDA平台为基于GPU的通用计算而定义的虚拟机和指令集
- 可以适配更多的GPU,C/C++源码转化为PTX这一步骤与GPU硬件无关
flow #
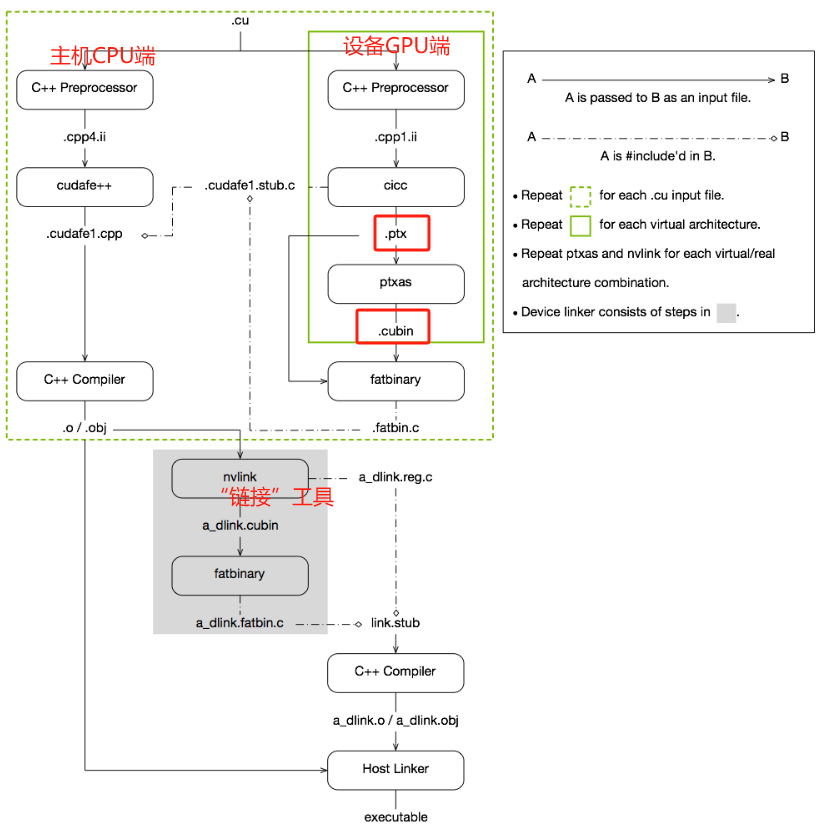
command #
nvcc -arch=compute_x1 -code=sm_x2 file.cu -o file_binary -run
-o 输出binary
-arch=compute_XY
- XY: 第一个数字X代表计算能力的主版本号, 第二个数字Y代表计算能力的次版本号

- 可以理解为对显卡版本的最低要求
-code=sm_XY
XY: 第一个数字X代表计算能力的主版本号, 第二个数字Y代表计算能力的次版本号
二进制cubin代码, 大版本之间不兼容 ,必须对应自己的GPU
指定真实架构计算能力的时候必须指定虚拟架构计算能力
定的真实架构能力必须大于或等于虚拟架构能力
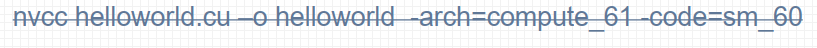
真实架构小版本之间是兼容的
-gencode arch=compute_XY –code=sm_XY
- 使得编译出来的可执行文件可以在多GPU中执行

- 执行上述指令必须CUDA版本支持7.0计算能力, 否则会报错
-arch=sm_XY
计算能力 #
不同版本CUDA编译器在编译CUDA代码时, 都有一个默认计算能力

GPU架构 #
不同的GPU架构之间, GPU指令集会有较大的差异,因此编译出的二进制可执行文件在不同的架构之间是不可以混用的
- 例如为帕斯卡GPU编译的扩大应用程序,很可能无法在福特GPU上运行
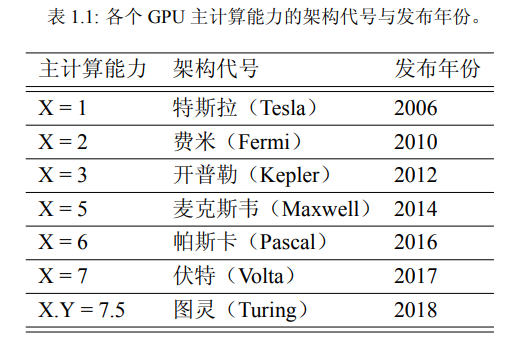

torch #
ATen库
性能对比 #
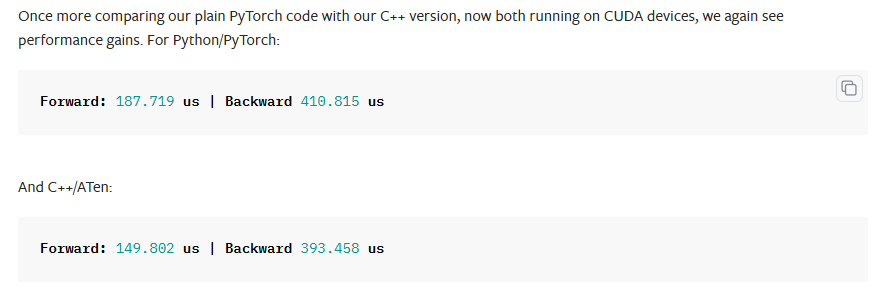
tutorial #
1. Introduction #
While the CPU is designed to excel at executing a sequence of operations, called a thread, as fast as possible and can execute a few tens of these threads in parallel, the GPU is designed to excel at executing thousands of them in parallel (amortizing the slower single-thread performance to achieve greater throughput).
GPU专门用于高度并行计算,因此设计了更多的晶体管用于数据处理,而不是数据缓存和流量控制。
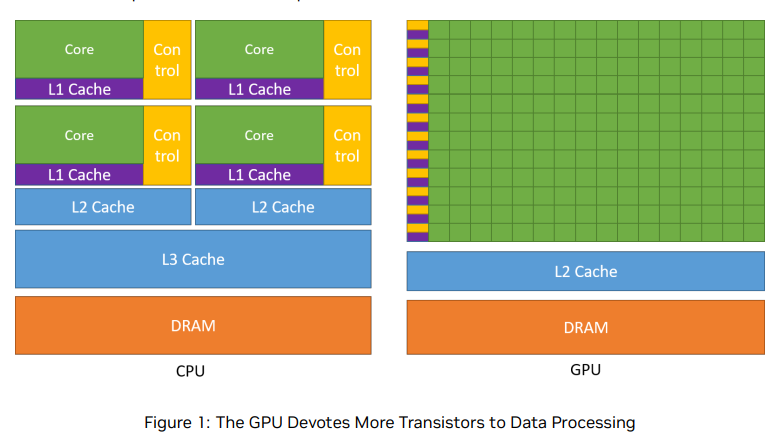
整体架构还是一样的,只是各个模块的量不一样?
GPU缓存较少,浮点计算单元较多
Applications with a high degree of parallelism can exploit this massively parallel nature of the GPU to achieve higher performance than on the CPU.
A Scalable Programming Mode #
At its core are three key abstractions — a hierarchy of thread groups, shared memories, and barrier synchronization — that are simply exposed to the programmer as a minimal set of language extensions.
2. Programming Model #
Kernels #
install #
- wsl下的安装
- CUDA C++ Programming Guide
- CUDA 所有相关官方文档
- An extensive description of CUDA C++ is given in Programming Interface.
参考 #
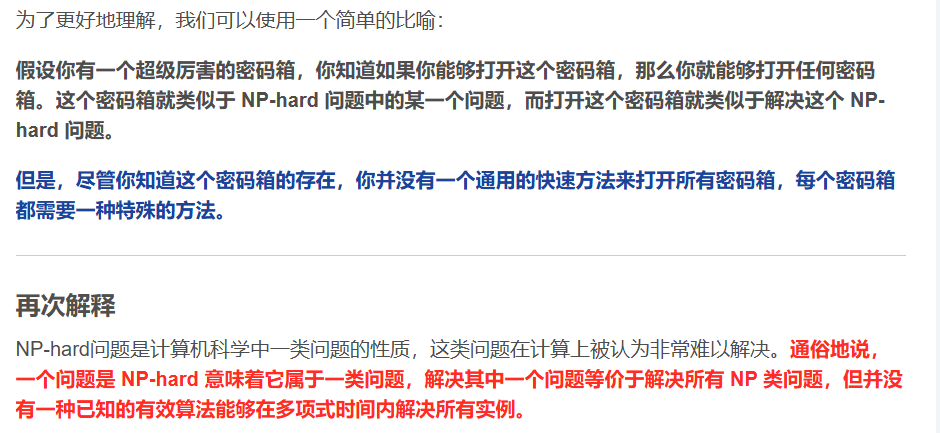
NP问题 #
基本概念: #
约化:

多项式
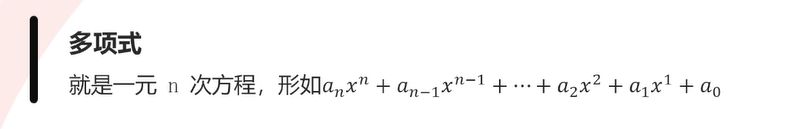
P问题 #
定义:一个可以在多项式时间复杂度内解决的问题。 例如:n个数的排序问题(不超过0(n^2^))
NP问题 #
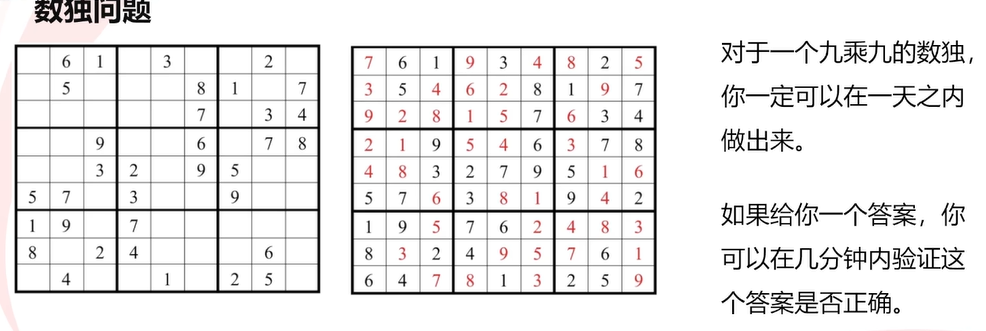
定义:可以在多项式的时间里验证一个解的问题。即给出一个答案,可以很快地(在多项式时间内)验证这个答案是对的还是错的,但是不一定能在多项式时间内求出正确的解。
举例:
1.数独问题:

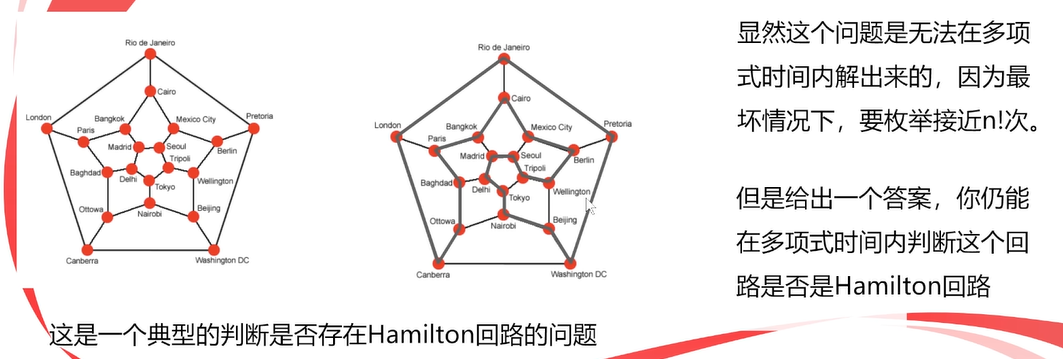
2.hamilton问题:

NP-hard #
定义:任意NP问题可以在多项式时间内约化成该问题即为了解决NP问题A,先将问题A约化为另一个问题B,解决问题B同时也间接解决了问题A。问题B就是一个NP难问题
举例:旅行商最短路径问题
设一个推销员需要从香港出发,经过广州,北京,上海,…,等n个城市,最后返回香港。 任意两个城市之间都有飞机直达,但双向的票价不等。求总路费最少的行程安排。
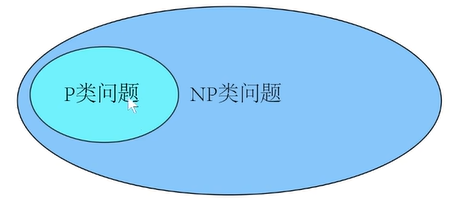
分析:想要知道所有方案中花费最少的,必须检查所有可能的旅行安排才能找到,即**(n-1)!种方案,很显然这不是P问题(不是多项式)。给出任意一个行程安排,你能算出它的总路费,但无法在多项式时间内验证这条路是否是最短路**。所以不是NP问题。(下图纯绿色部分)

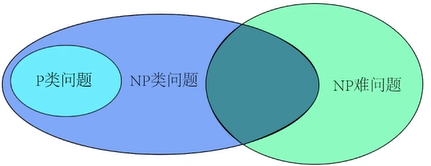
NP-Complete问题 #
定义:所有既是NP问题,又是NP难问题的问题 即一个NP问题,任意的NP问题可以约化到它:
NPC问题只能暴力求解?
举例:
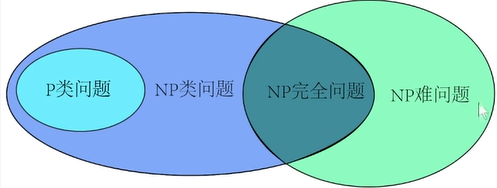
旅行商问题(限制花费)
设一个推销员需 要从香港出发,经过广州,北京,上海,…,等n个城市,最后返回香港。 任意两个城市之间都有飞机直达,但双向的票价不等。现在假设公司给报销C块钱问是否存在一个行程安排,使得他能遍历所有城市,而且总的路费小于C?

python和c/c++的区别 #
主要区别 #
1. 性能 #
C++ 性能优势 #
编译型语言
:
- C++ 是编译型语言,代码在执行前被编译成机器码,因此运行时不需要额外的翻译步骤,执行速度非常快。
手动内存管理
:
- C++ 提供对内存的直接控制(如
new/delete或malloc/free),允许开发者优化性能。
- C++ 提供对内存的直接控制(如
零运行时开销
:
- C++ 不依赖虚拟机,运行时没有垃圾回收器等额外的开销。
硬件亲和性
:
- C++ 可以直接控制硬件资源(如寄存器、指令级优化),这在需要高性能的场景(如嵌入式系统、游戏引擎)中非常重要。
Python 性能劣势 #
解释型语言
:
- Python 是解释型语言,代码需要在运行时由解释器(如 CPython)逐行翻译成机器码,这会显著降低运行速度。
动态类型系统
:
- Python 的动态类型检查在运行时执行,增加了额外的开销。
垃圾回收
:
- Python 使用自动垃圾回收器(如引用计数和标记清除),虽然减少了内存管理的复杂性,但增加了运行时负担。
全局解释器锁 (GIL)
:
- Python 的多线程性能受限于 GIL,无法充分利用多核 CPU,影响计算密集型任务的效率。
典型性能对比 #
- 计算密集型任务:C++ 通常比 Python 快 10~100 倍。
- I/O 密集型任务:差距较小,但 C++ 仍略占优势。
- 优化潜力:C++ 提供更低级别的优化工具,性能可以进一步提升。
2. 开发效率 #
Python 优势
:
- 简洁的语法,开发效率高。
- 动态类型和丰富的标准库适合快速原型开发。
C++ 劣势
:
- 语法复杂(如模板、指针管理)。
- 手动内存管理增加开发难度。
3. 类型系统 #
- C++:静态类型语言,变量类型在编译时确定,提供更好的错误检查和性能优化。
- Python:动态类型语言,变量类型在运行时确定,灵活性高但容易导致运行时错误。
4. 内存管理 #
- C++:支持手动内存分配和释放,适合需要精准控制内存的场景,但容易出现内存泄漏或悬挂指针问题。
- Python:自动垃圾回收,降低了内存管理复杂性,但会带来性能损耗。
5. 库支持 #
- C++:广泛支持高性能库(如 STL、Boost),适合底层开发。
- Python:丰富的第三方库,尤其在数据科学(NumPy、Pandas)、机器学习(TensorFlow、PyTorch)领域占据主导地位。
6. 使用场景 #
C++ 适用场景 #
- 高性能需求:游戏开发、嵌入式系统、操作系统、实时应用。
- 硬件控制:与硬件交互的系统。
Python 适用场景 #
- 快速开发:脚本工具、原型开发。
- 数据科学和机器学习:开发速度比性能更重要。
- 自动化任务:如 Web 爬虫和测试。
性能优化方法 #
1. Python 提高性能的方法 #
- 使用 JIT 编译器(如 PyPy)代替 CPython。
- 关键代码用 C/C++ 编写,并通过扩展(如 Cython、SWIG)调用。
- 使用并行库(如 multiprocessing)绕过 GIL。
2. C++ 提高开发效率的方法 #
- 使用现代 C++(如 C++11/14/17)特性(如智能指针、自动类型推导)。
- 借助库(如 Boost)减少手动开发复杂性。
总结 #
| 特性 | C++ | Python |
|---|---|---|
| 性能 | 高,适合高性能需求 | 较低,适合快速开发 |
| 开发效率 | 较低,语法复杂 | 高,语法简洁 |
| 类型系统 | 静态类型,编译时检查 | 动态类型,运行时检查 |
| 内存管理 | 手动管理,精准控制 | 自动管理,简单易用 |
| 生态系统 | 底层开发库丰富,适合高性能应用 | 第三方库广泛,适合数据科学与快速开发 |
| 适用场景 | 游戏开发、嵌入式系统、实时应用 | 数据分析、机器学习、脚本工具 |
对于需要高性能或与硬件交互的任务,C++ 是更好的选择;而 Python 则适合对开发效率要求较高的场景,如快速原型、数据分析和机器学习。